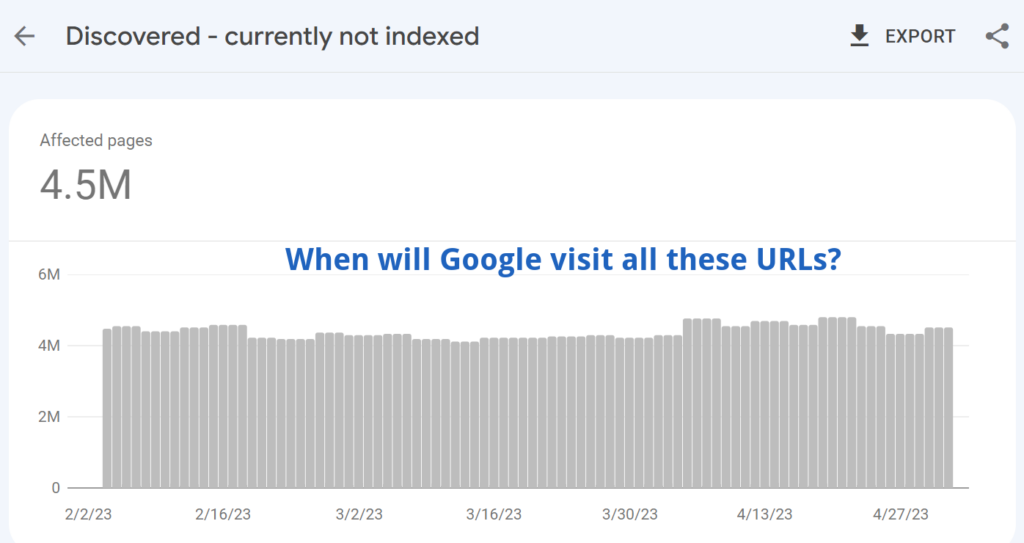
“Discovered – Currently not indexed” is a common indexing issue in Google Search Console. It means Google knows your page exists, but hasn’t visited it yet.
This article explains why this happens and provides solutions.
There are four reasons for “Discovered – currently not indexed”:
Let’s explore the reasons and solutions for this problem.
Google tries to limit crawling on slow websites to avoid overloading servers.

As a result, many pages can be classified as: “Discovered – currently not indexed”.
Why does this happen? As Google’s Webmaster Trends Analyst, Gary Illyes, pointed out, Google aims to be a “good citizen of the web.” Faster websites allow for more crawling and indexing.
The rule is simple:
To analyze Performance we recommend using ZipTie.dev. As you can see on the screenshot below, this website has massive problems with performance – many parameters including response time are very weak, much worse than other websites in our database.
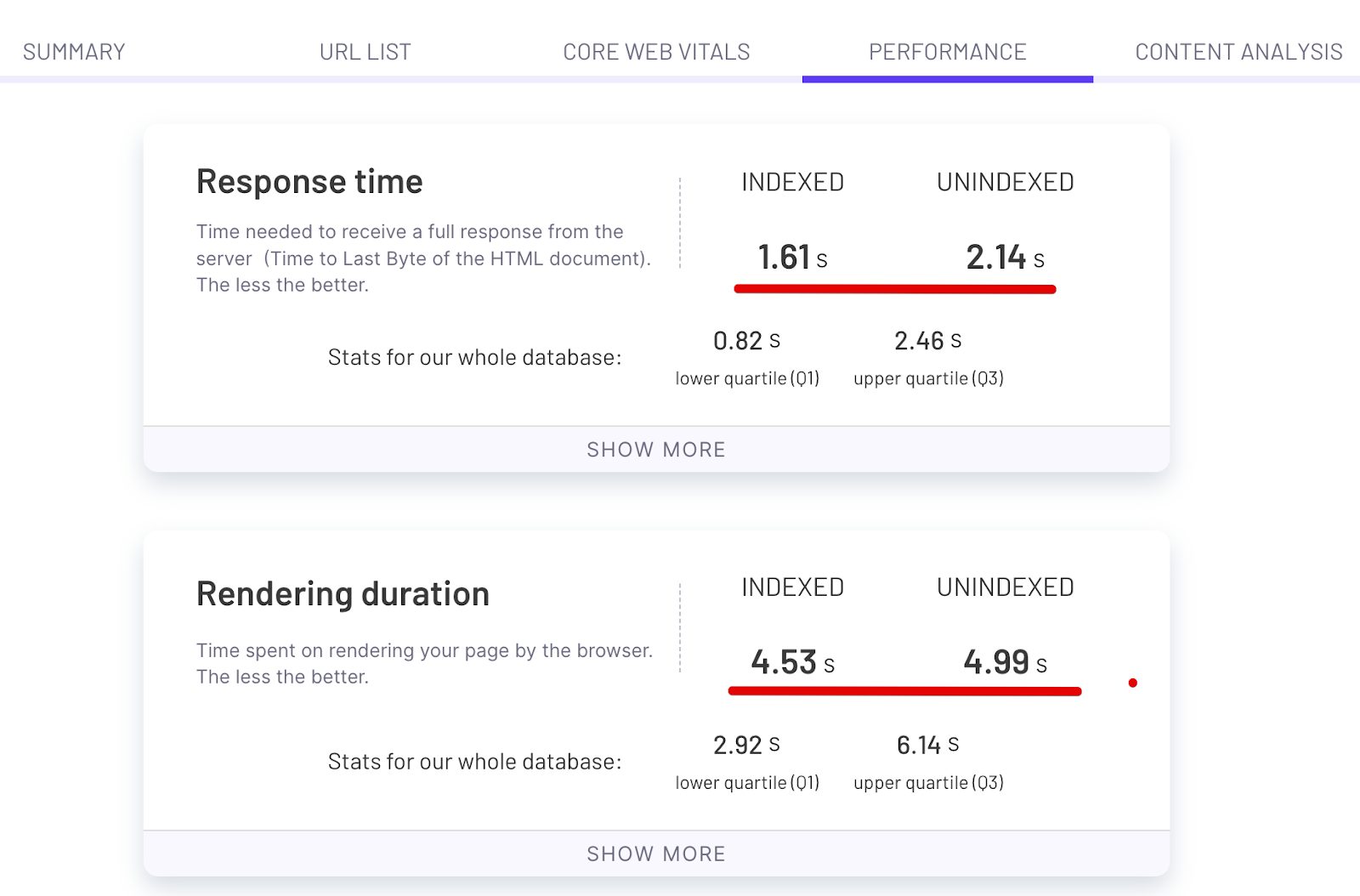
This is something that can negatively affect indexing. As a result, Google may classify many pages as “Discovered – currently not indexed”.
Google’s Page Indexing Report documentation illustrates that the typical cause of the “Discovered – currently not indexed” message is due to Google not wanting to overload the site.
Based on my observation, this is extremely inaccurate. In fact, it’s just one of many factors.
On many occasions, I’ve seen websites with fast servers that were still struggling with the “Discovered – currently not indexed errors.
Why? Because either crawl demand was extremely low, or Google was busy crawling other pages.
Your website competes with the entire internet for Googlebot’s attention. This applies to both new and established websites. For new websites, Google needs time to collect signals about your site. However, even well-established websites can struggle with crawl demand.
Which signals make Google crawl more? Google is not willing to release the details of its secret sauce. However, based on public information provided by Google, we can compile the following list of signals:
So you should find a way to optimize your website for these signals.
It may also be the case that while the crawl budget for your overall website is high, Google might choose not to crawl specific pages due to either a lack of link signals, predictions of low quality, or because of duplicate content.
Further explanations for each of these causes are provided below:
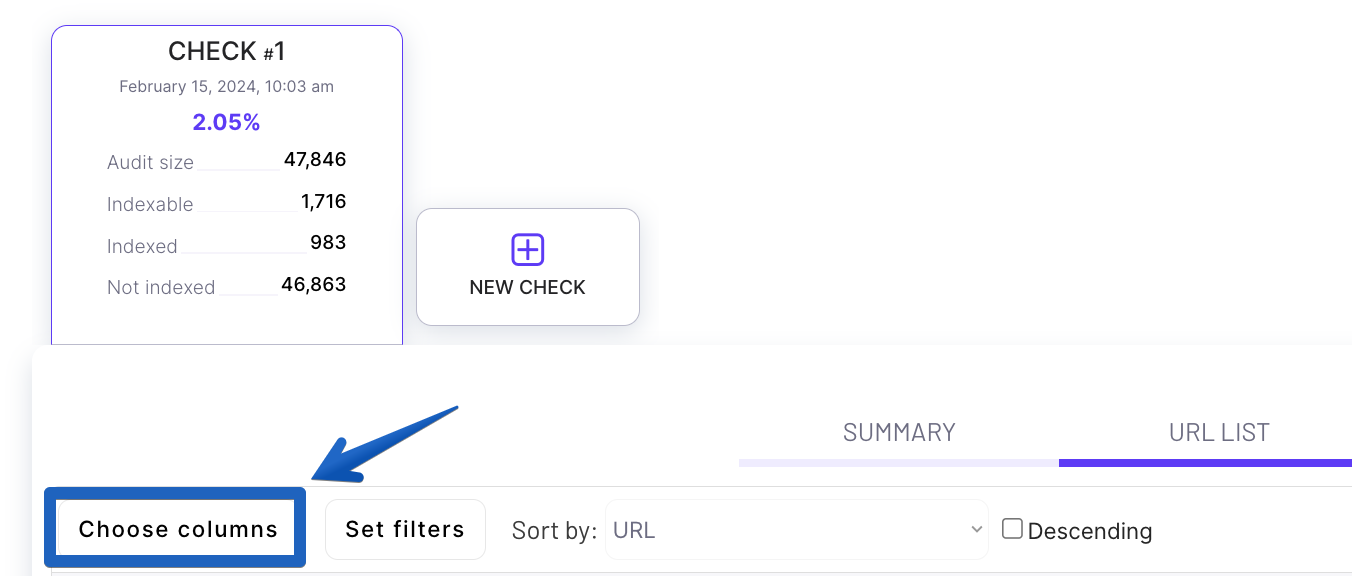
The first priority is to check if the problem with “Discovered – currently not indexed” is severe.
Go to Search Console and Indexing -> Pages and then scroll down to the Why pages aren’t indexed” section. Then check how many pages are affected. Is it just a small percentage of your website, or a massive part of it?
Then review a sample of affected pages. You can do this by clicking on “Discovered – currently not indexed”.
If there are just a few important pages classified as “Discovered – currently not indexed”, make sure that there are internal links pointing to them, as well as whether these pages are included in sitemaps. This easy fix should work in most cases.
If there are many important pages classified as “Discovered – currently not indexed” that means the issue is broader. Here’s your action plan:
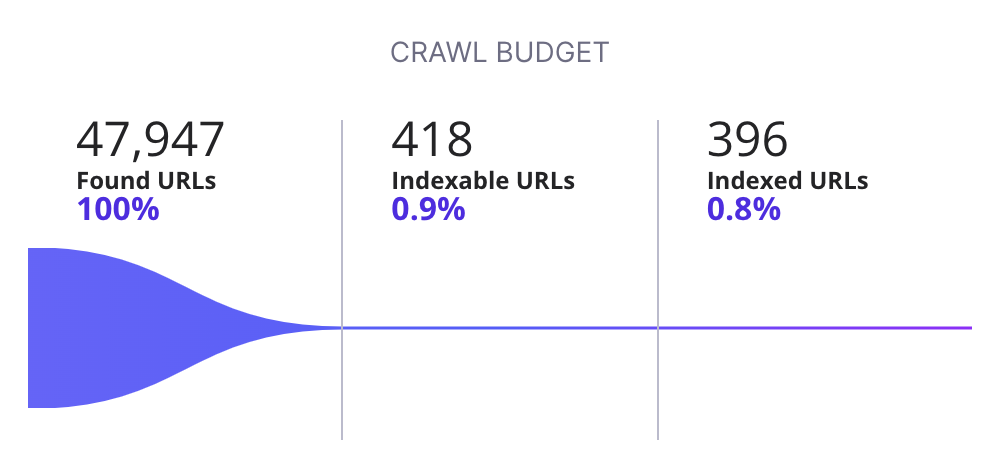
To analyze your crawl budget you can use ZipTie.dev. In this case just 1% of URLs are indexable, meaning 99% of URLs Google can visit are not intended for indexing. It’s a total waste of crawl budget: as for every 1 indexable URL, Google has to visit 99 non-indexable URLs.
What is “Discovered Currently Not Indexed”?
“Discovered Currently Not Indexed” means Google knows about your page (through sitemaps or internal links) but hasn’t added it to its search index. This is different from not being crawled – the page may have been crawled but Google decided not to index it.
What causes pages to be “Discovered Currently Not Indexed”?
Common causes include low-quality or duplicate content that Google chooses not to index, limited crawl priority for new or less authoritative sites, technical issues preventing proper indexing, and content that doesn’t meet Google’s quality thresholds.
How can I check which pages are affected?
In Google Search Console, go to “Pages” under “Index” section, then find “Discovered – currently not indexed” under “Why pages aren’t indexed”. This shows all affected URLs.
Why isn’t Google indexing my important pages?
Google might not index pages if they’re similar to existing indexed content, the content quality is deemed insufficient, technical issues make indexing difficult, or the site’s overall authority is still developing.
How can I fix this issue?
Focus on these key areas: improve unique, high-quality content, ensure proper technical setup (clean URLs, proper internal linking), build site authority through quality backlinks, remove or fix low-quality and duplicate content, and use tools like Google PageSpeed Insights to check technical health.
When should I be concerned?
Be concerned if many important pages remain unindexed, the issue persists for several weeks, your competitors’ similar content is being indexed, or you’re losing traffic due to non-indexed pages.
By following these steps, you can address the “Discovered – Currently not indexed” issue in Google Search Console and improve your website’s visibility in the search results. Keep monitoring your website’s performance in the Search Console and make necessary adjustments to maintain optimal visibility.
Crawled – currently not indexed is one of the most common reasons that a page isn’t indexed. Let’s explore how to fix this issue on your website!
When Google shows “Crawled – currently not indexed” in Search Console, it means Google has seen your page but decided not to include it in search results. This typically happens when Google finds issues with your content quality or technical setup. You can fix this by making your content better, solving any technical problems, and linking to the page from other pages on your site. Tools like Google Search Console and ZipTie.dev can help you track and improve how well Google indexes your pages.
To find affected pages, go to Google Search Console and click on Indexing -> Pages.
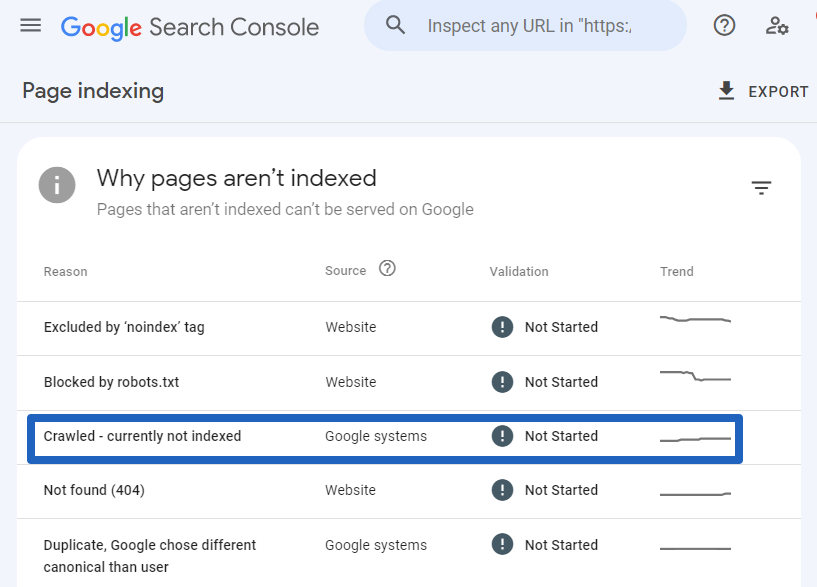
Click on “Crawled – currently not indexed” to see a sample of up to 1,000 URLs.
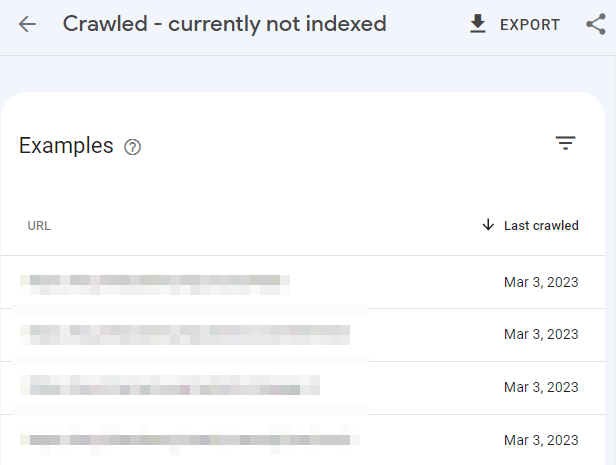
These are the three most common reasons:
Let’s start with the most surprising reason: Google isn’t convinced about the website overall.
It might be surprising, but a page might not be indexed because Google isn’t convinced about the overall quality of the whole website.
Let me quote John Mueller:
As ZipTie.dev shows, in the case of Growly.io the vast majority of pages are indexed, so we assume this website is not suffering from quality issues.
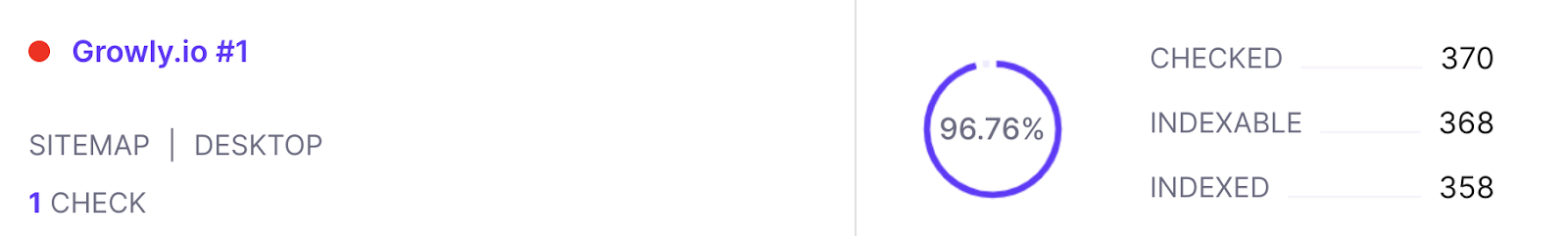
Sometimes a page might be high quality, but Google can’t see its value because it can’t render the website properly. This could be due to JavaScript SEO issues.
So let’s imagine your main content is generated by JavaScript. If Google cannot render your JavaScript content, then your main content won’t be visible to Google and Google will wrongly(!) judge your pages as low quality.
This can eventually lead to both indexing and ranking problems.
You can use ZipTie to fully check JavaScript dependencies. This way you will see a list of pages with the highest JavaScript dependencies.
Then if you check them in Google Search Console and see they are classified as Crawled Currently not indexed, it’s a sign it may be caused by JavaScript SEO issues.
Let’s take it step by step.
While you create an audit, set an option for JavaScript rendering.
Then you can see the average JS dependency:
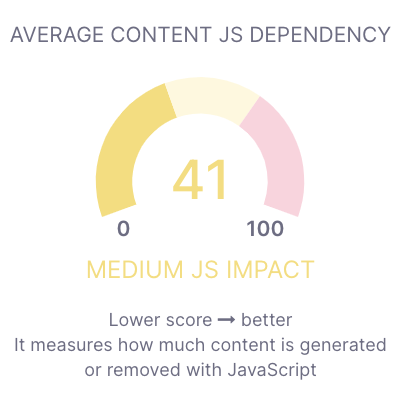
In this case, JavaScript has a medium impact on the website which indicates the website may have indexing problems due to JavaScript.
Then we can navigate to the list pages with the highest JS dependency:
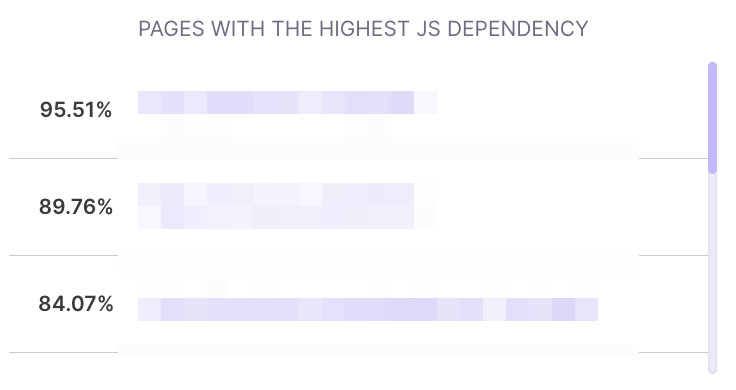
Now we know which elements rely on JavaScript the most. Now it’s time to check if Google can properly render your page.
I explain this in my article: How to Check if Google properly renders your JavaScript content.
Google aims to provide users with relevant and high-quality content. If a page is low quality or outdated, it might not be indexed.
To objectively assess your content’s quality, use Google’s list of Content and Quality questions.
What I do quite often is visit the Content Analysis section of ZipTie.dev.
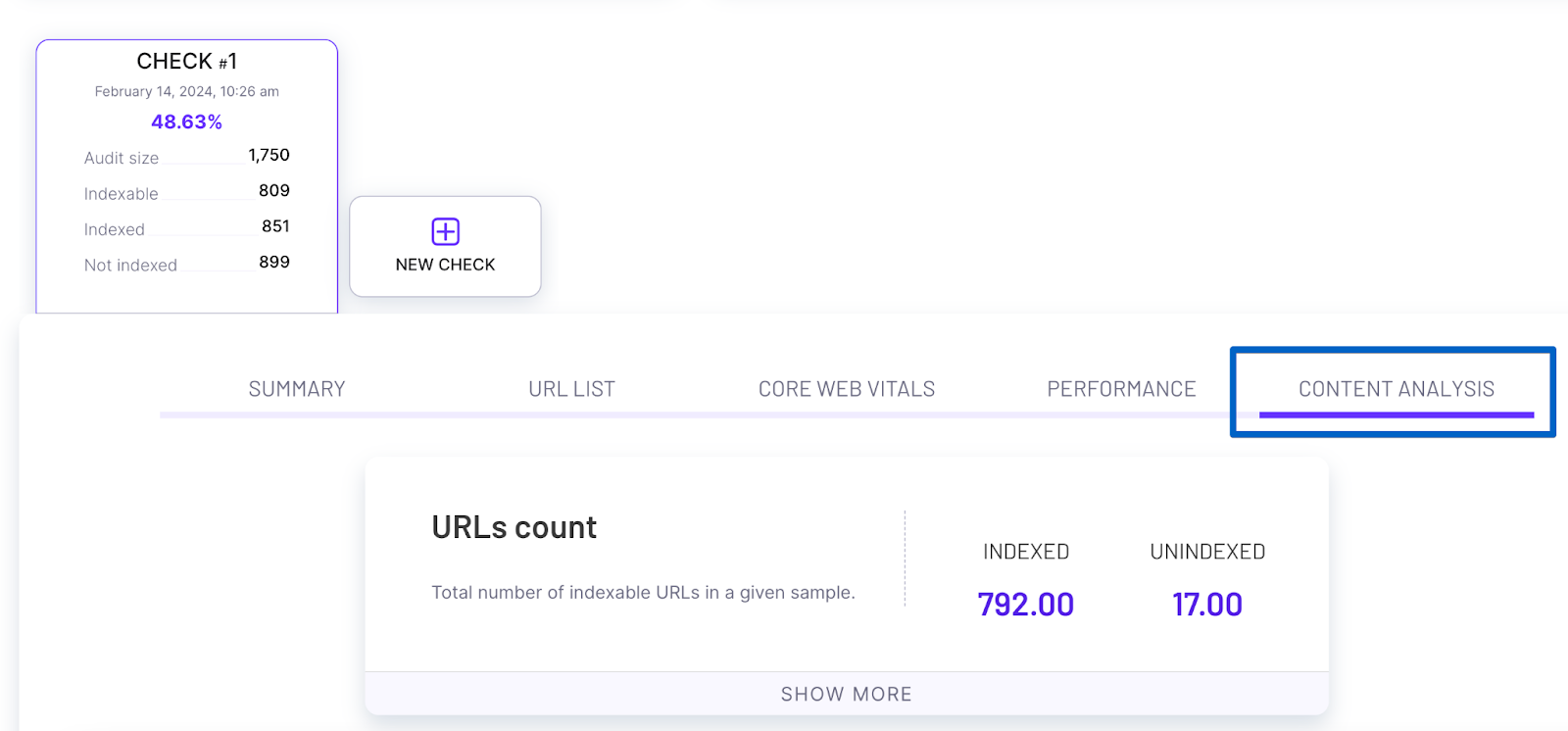
And then I scroll through this report to see the differences between pages that are indexed and pages that are not indexed.
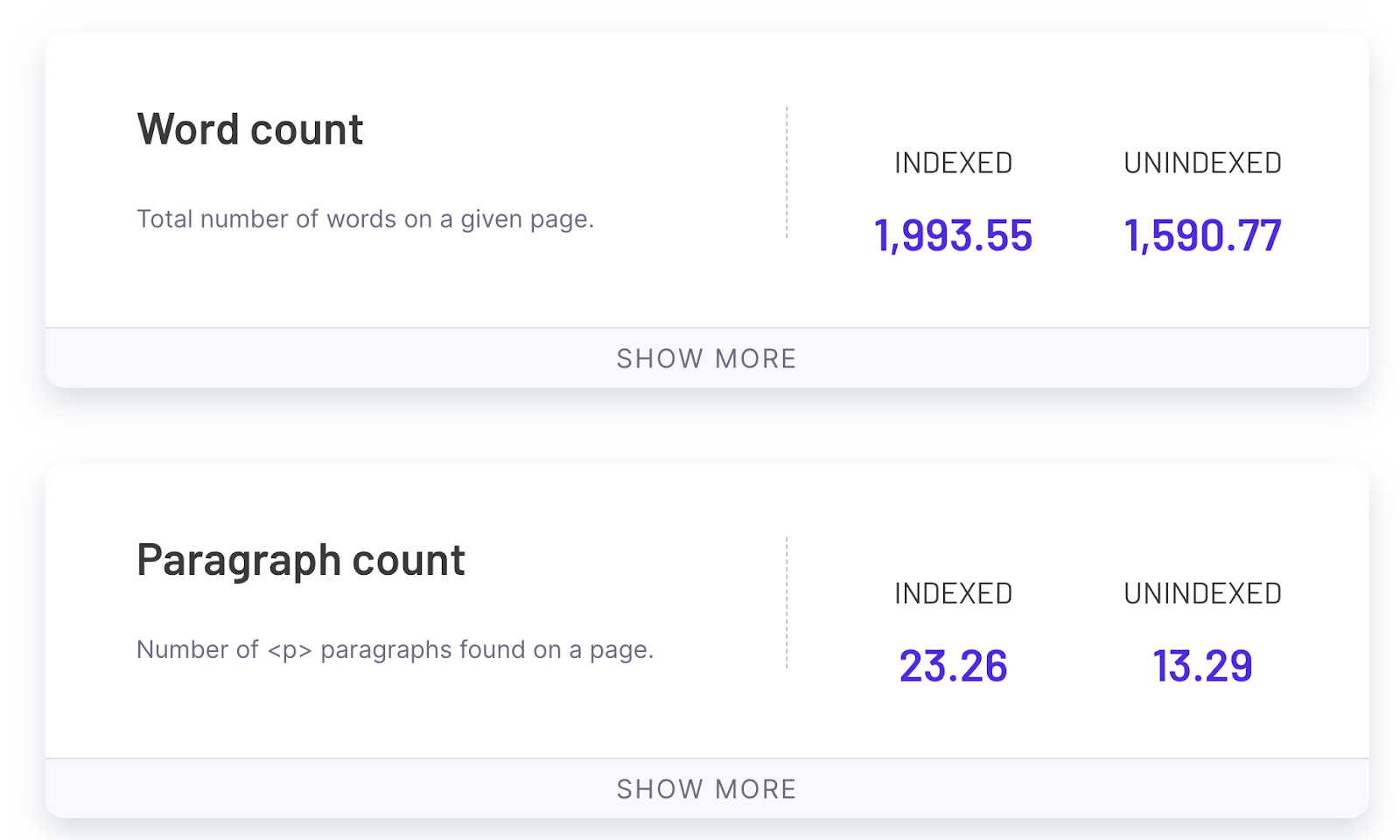
As we can see on the screenshot above, it seems the average number of paragraphs for pages that aren’t indexed is 13 which is 44% lower than in the case of pages that are indexed. We can then formulate the hypothesis that Google is not willing to index pages with lower amounts of content in the case of this website.
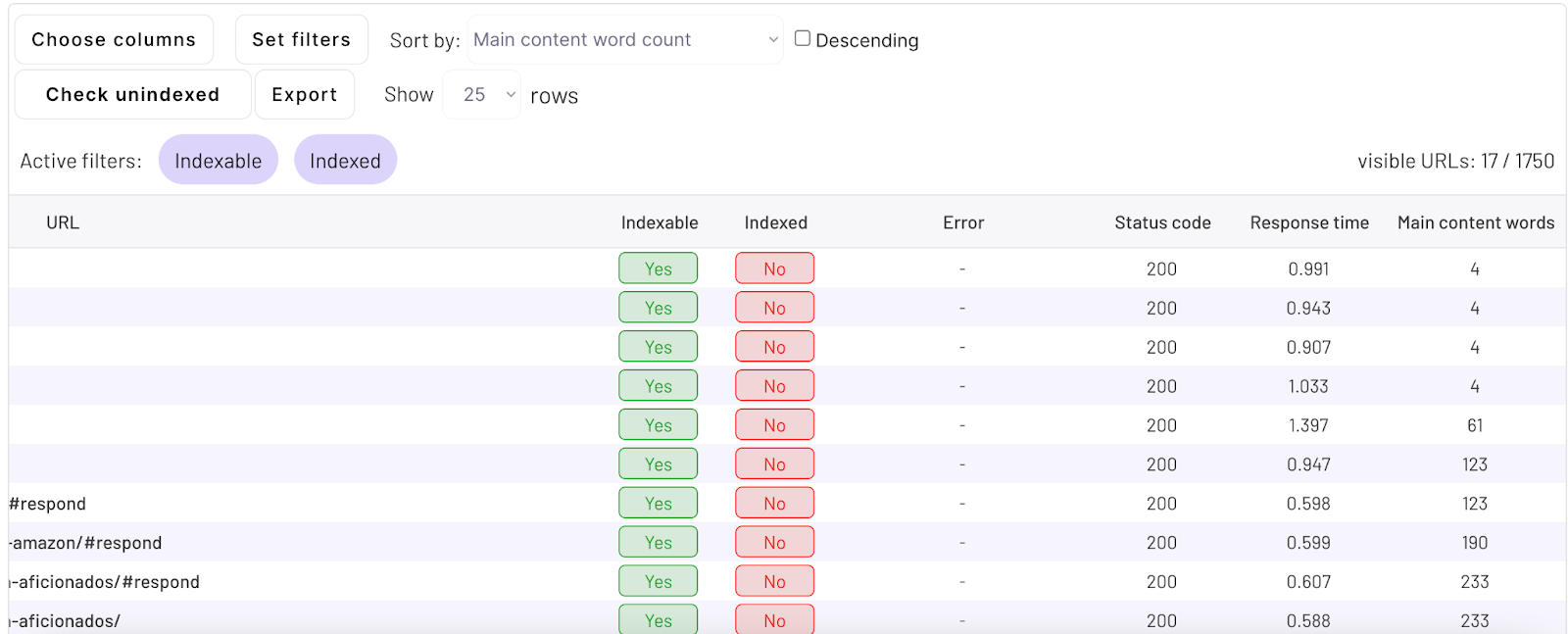
Also, GSC shows limited data – up to 1000 URLs. What I like is to use ZipTie and set filters: “Indexable: yes”; “Indexed: no”.
Then I analyze patterns by looking at the URLs. As we can see on the screenshot below what tends to be not indexed is:
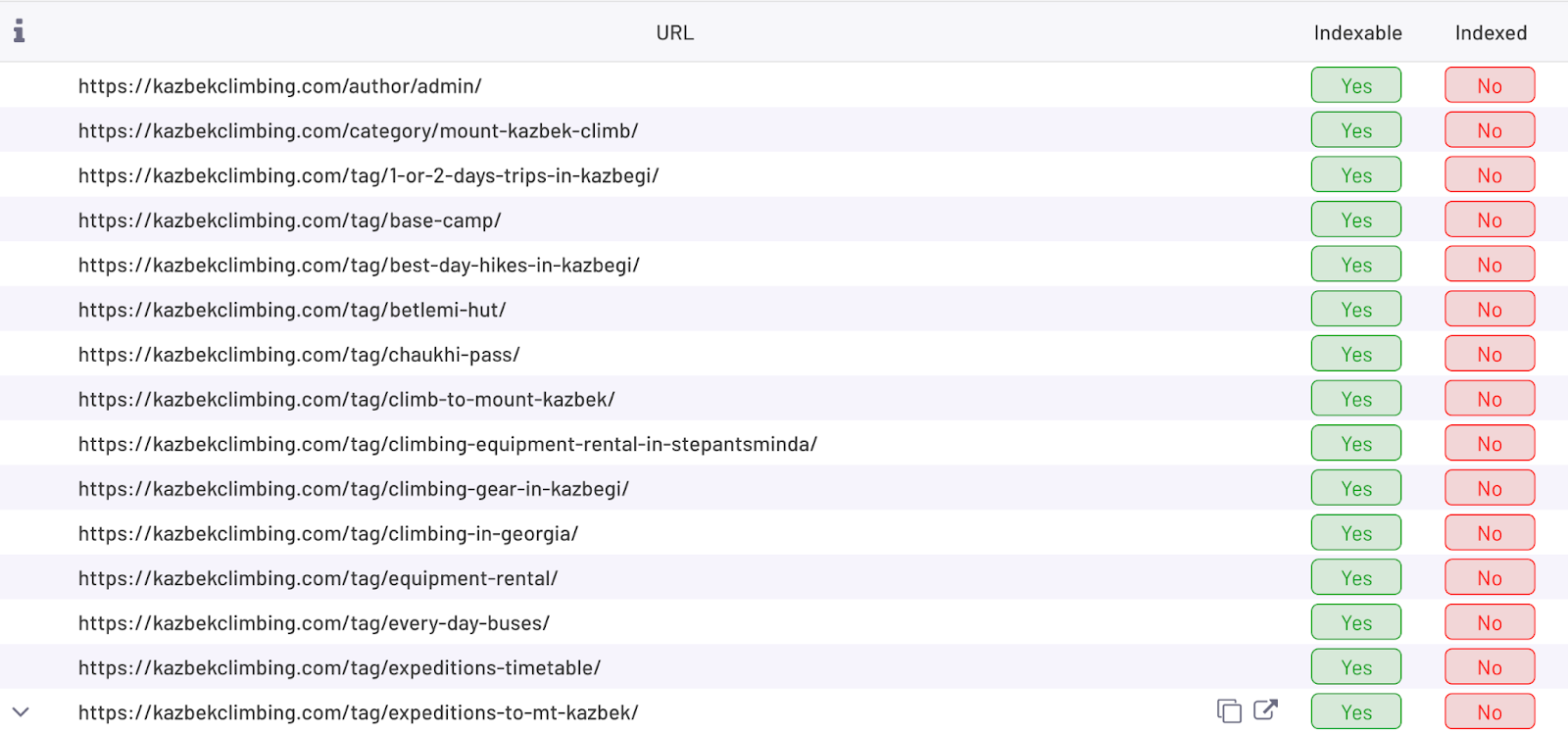
Another option is to sort by main content word count. Pages with the lowest number of main content words are likely to be not indexed in Google (Google is not willing to index pages with little to no content).
If you want to make them indexed, follow the workflow I present in the latter part of the article.
At a glance, the workflow to fix “Crawled – but not Indexed” is very easy:
All the steps are presented on the diagram below:
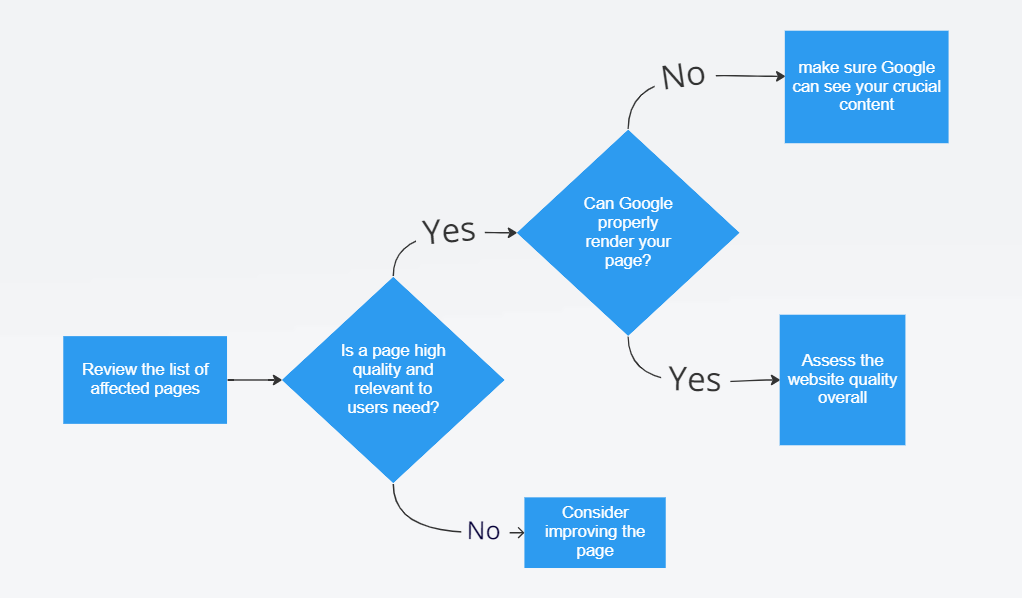
First, you need to check if your content is good enough and if there are any technical problems. Make your content better by adding unique, helpful information. Also check if JavaScript is causing any issues. Once you’ve made these fixes, go to Google Search Console and ask Google to index your page.
In this article, I explained that one of the reasons for the status “Crawled – but not Indexed” is when a previously indexed page gets removed from the index. This occurrence is quite common, particularly during core updates.
Luckily, ZipTie.dev provides an Indexing Monitoring module that can help you with this. By using ZipTie, you can easily identify the specific URLs that have been deindexed by Google.
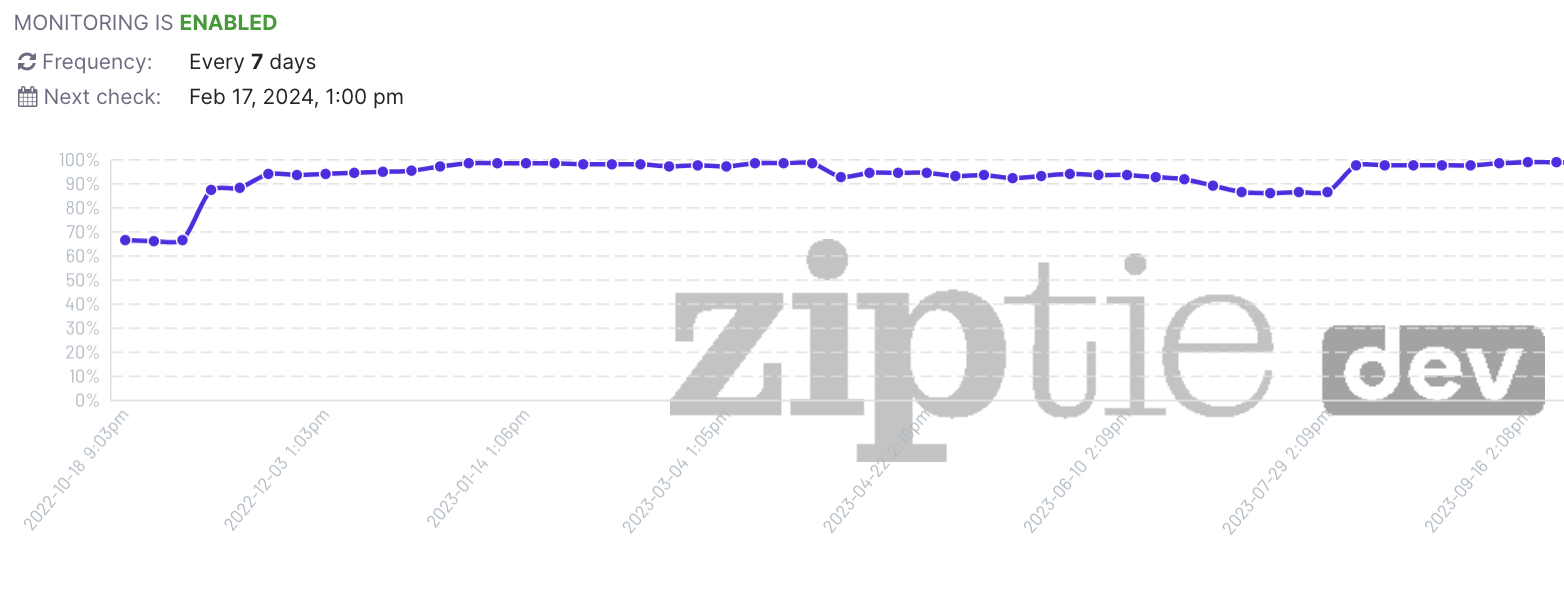
Don’t hesitate to give it a try and see the benefits for yourself! Check out our 14-day trial FREE OF CHARGE.
JavaScript is a very popular technology. Most websites have at least one element that is generated by JavaScript.
I remember the first JavaScript SEO experiments by Bartosz Goralewicz back in 2017 when he showed Google had MASSIVE issues with indexing and ranking JavaScript websites.
Although Google went through a long journey, now in 2024 Google still has issues with JavaScript websites.
It can cause problems both with indexing and ranking.
Let’s start with indexing. Issues with rendering can cause problems with:
Suprised? Let me introduce the vicious cycle of JavaScript SEO:
Step 1: Problems with rendering: If Google can’t properly render your content, then Google will judge your page based on just a part of your content.
Step 2: Then Google will wrongly(!) classify your content as low quality and put it under Crawled currently not indexed or Soft 404.
Another risk: if your JavaScript dependency is high, and rendering fails, then all that Google can see is boilerplate content and may classify your page as duplicate and won’t index it.
Is it only an indexing problem? Of course not! When Google has problems with rendering your page, then Google judges your content based on just a small part of the content. As a consequence, it will will rank suboptimally.
So it’s both a ranking and indexing problem.
In this guide I will show you how to identify problems with JavaScript rendering to let you avoid both ranking and indexing issues.
The first step is to find pages with the highest JavaScript dependency. You can do it using ZipTie.dev.
Assuming you audited your website using ZipTie with JavaScript mode on, you need to click on “Choose columns”:
Then tick the “JS dependency” column;
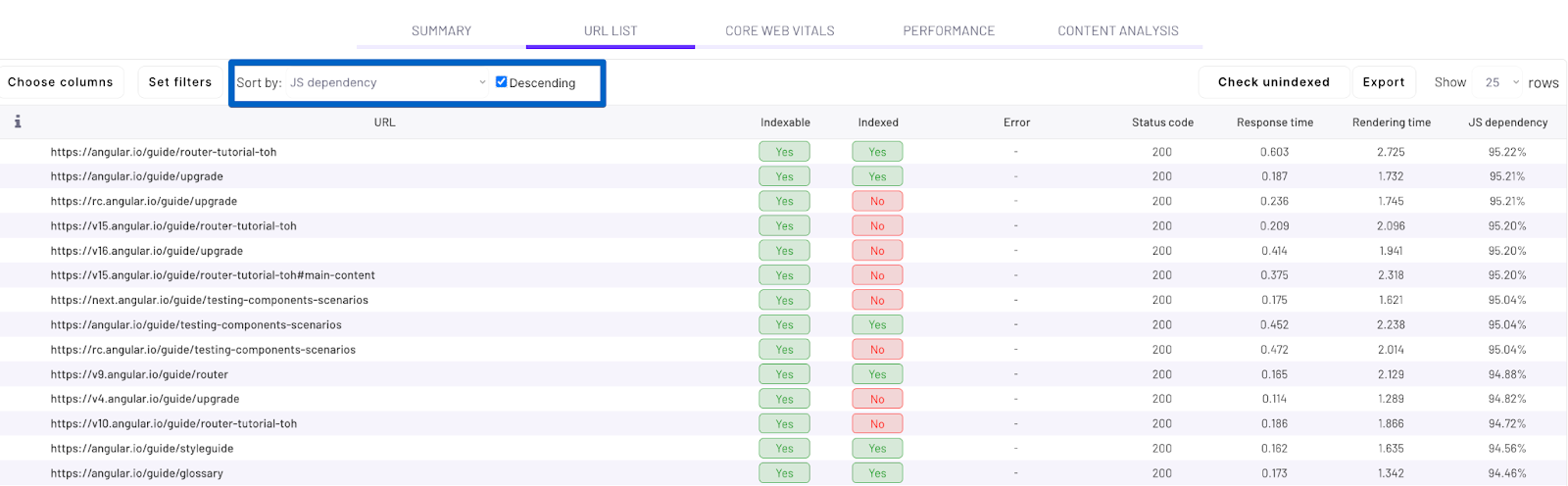
Then the final step is to find URLs with the highest JS dependency. To do this, sort by “JS dependency” descending.
Then choose a sample of URLs you want to analyze. If you have an e-commerce store, select a sample:
For each of the groups, try to select URLs with the highest JS dependency, because this will increase your chances of spotting the issue with JavaScript SEO.
Now we know which URLs have the highest JS dependencies as well as having selected a sample of URLs to be checked.
Now we can check which elements are generated by JavaScript. For this, we can use WWJD (What would JavaScript Do).
For the purpose of this article, let’s check the homepage of Angular.io.
And WWJD will show you the output with two versions. On the left, is the version with JavaScript disabled, and on the right is the version with JavaScript enabled:
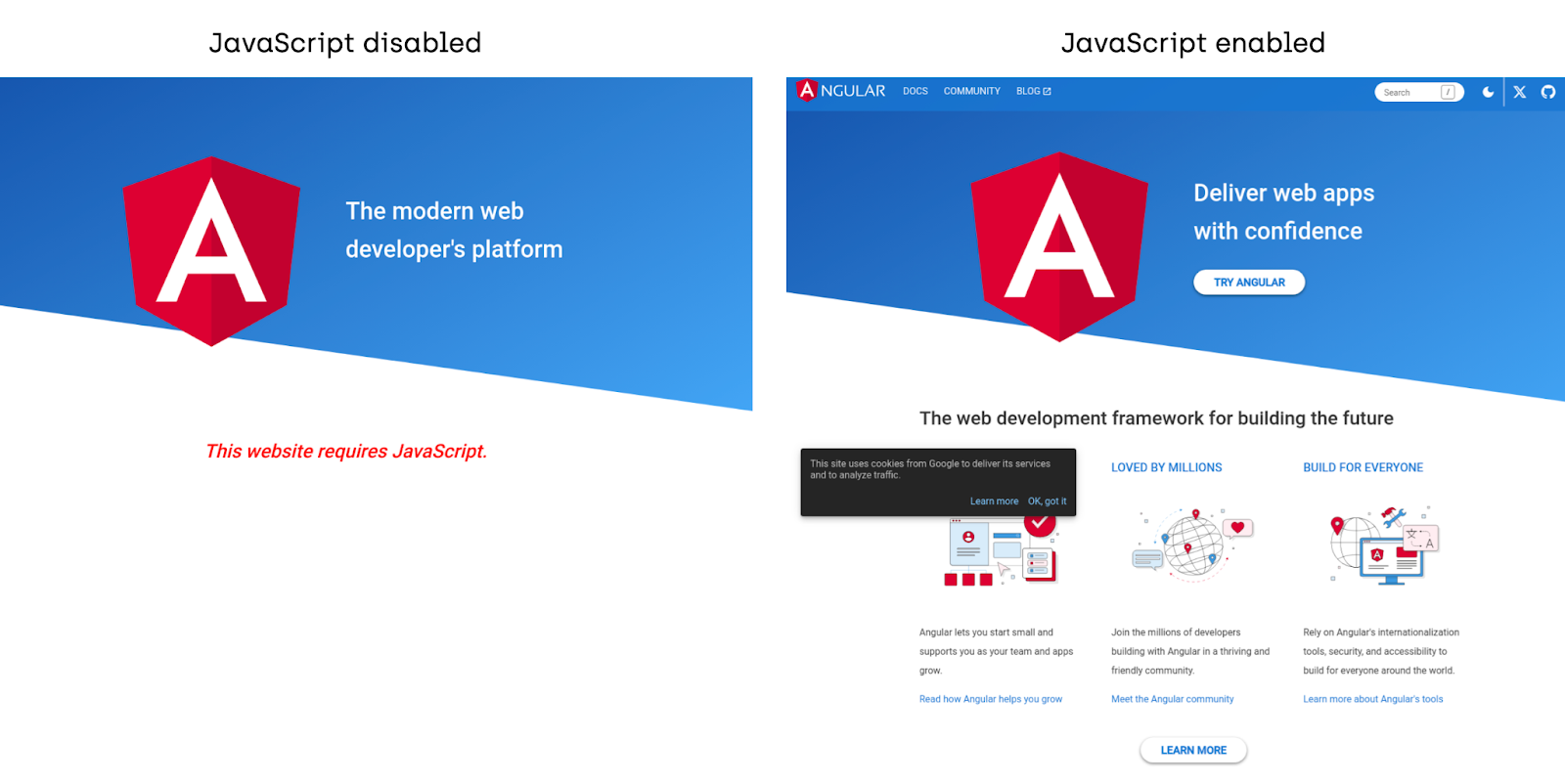
You can then compare them visually.
As you can see JavaScript is fully responsible for generating content. With JavaScript switched off the only content that appears is the phrase: “The modern web developer’s platform” and “this website requires JavaScript”.
So in this step we identified content generated by JavaScript. Now we can save the notes with parts of the content generated by JavaScript:
We already know the impact of JavaScript on our website.
The next step is to use the URL Inspection tool in Google Search Console to see how Google renders your content.
In Google Search Console click on URL inspection:
And then paste the URL you want to check. It will take a few moments to get a response from Google Search Console.
Finally, Google will tell you if a page is indexed. Depending on this, you will have to follow a slightly different algorithm. But don’t worry, it’s quite easy.
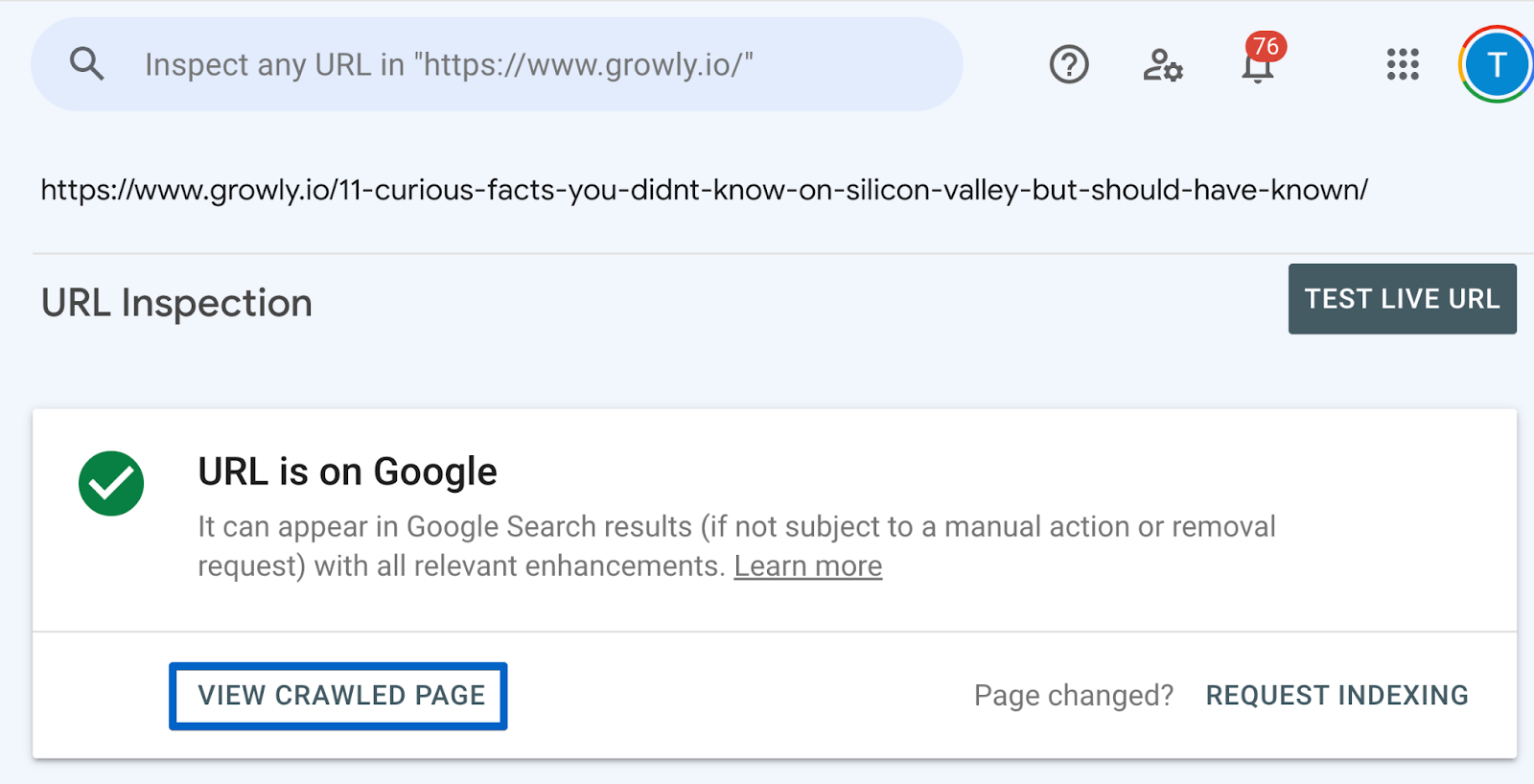
If the page is indexed:
If the page is indexed (you can see a tick: “URL is on Google”), click on: “View crawled page”.
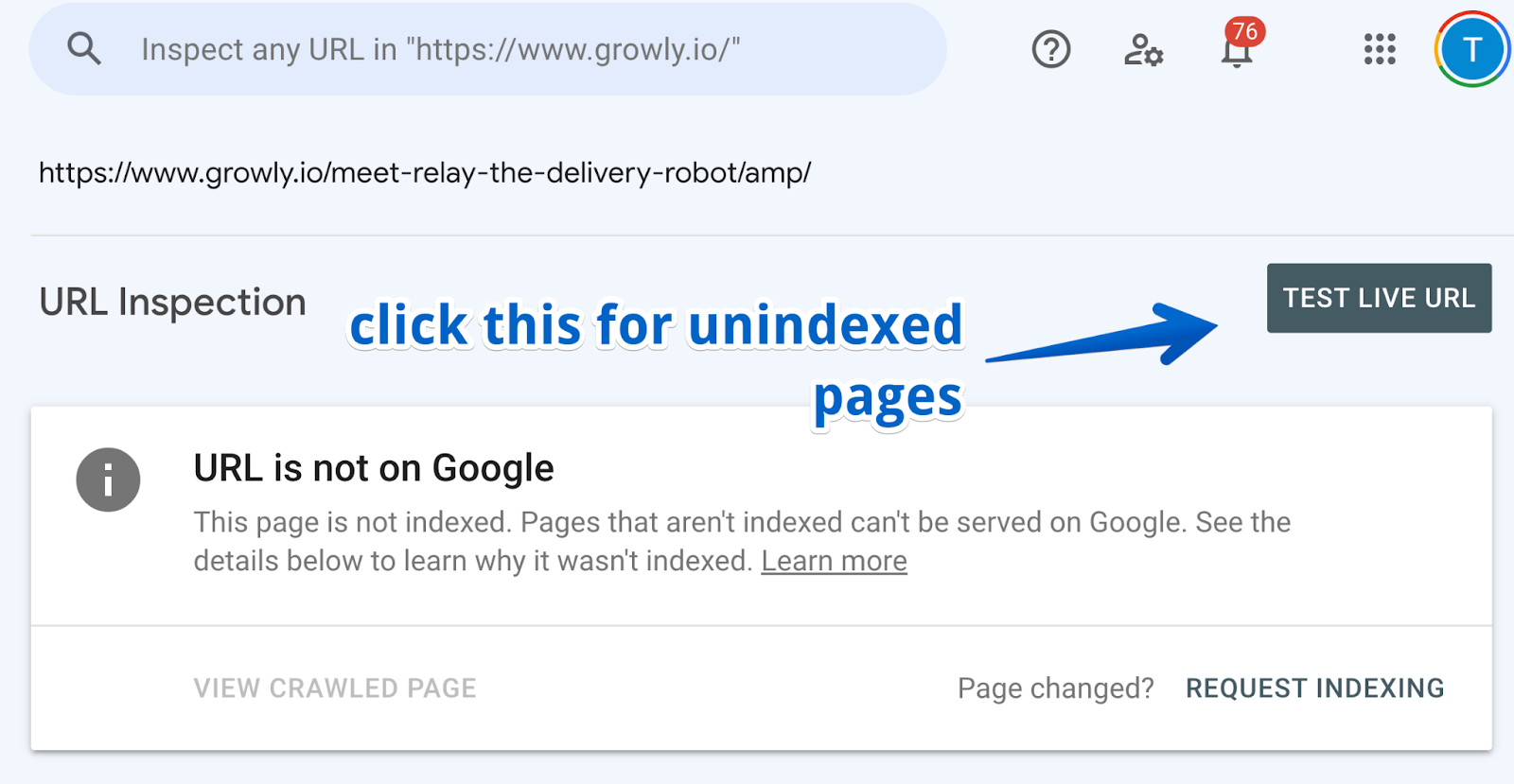
If the page is not indexed:
If the page is not indexed, instead of clicking on “View crawled page”, you need to click on: “Test live URL” beforehand.
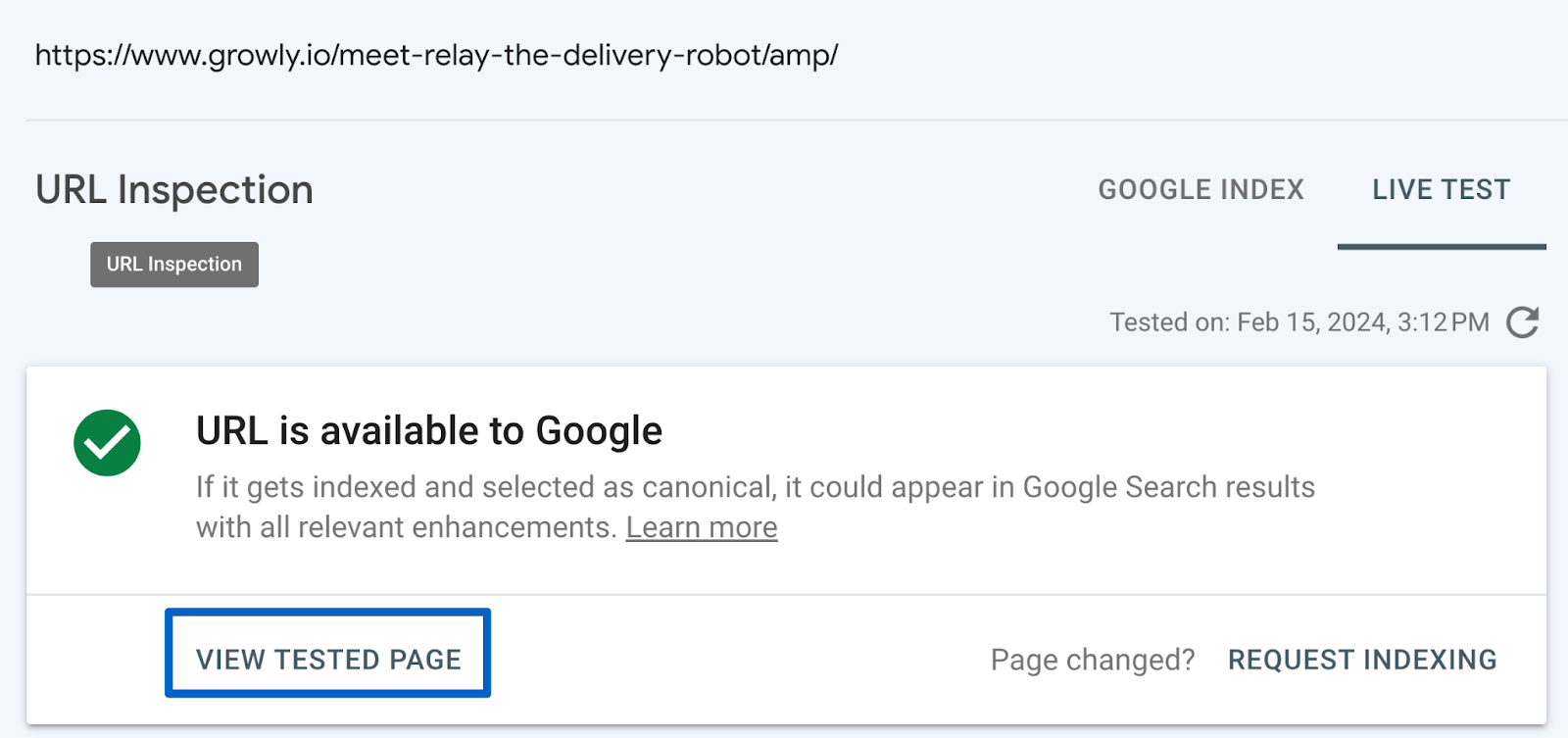
And then, finally, you will be able to click on “View crawled page”:
Now it’s time for the most important part.
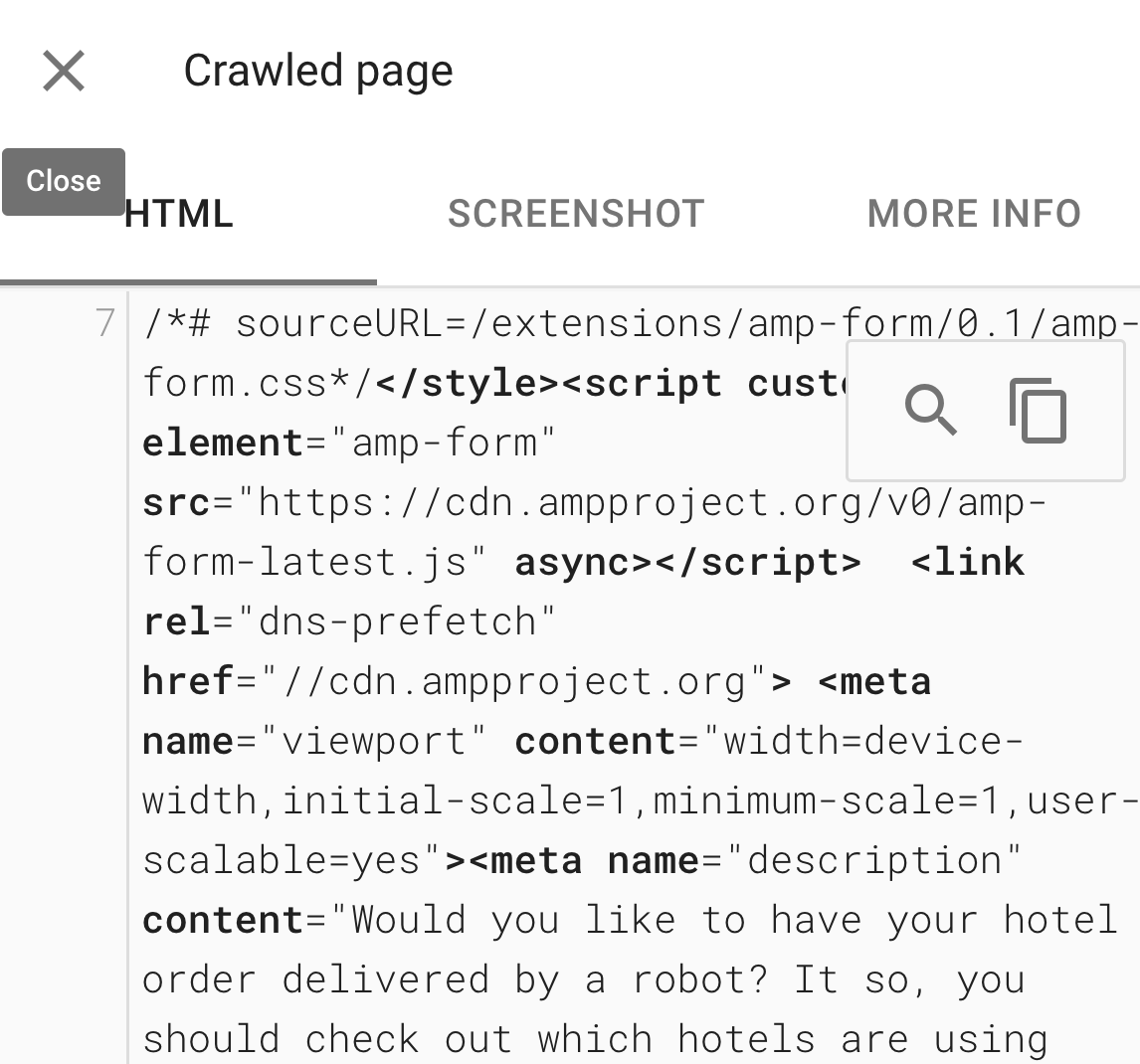
Once we click on View crawled page, then we can click on the HTML tab to see how Google rendered the code.
Type CTRL F (Or Command F for Mac) and type each crucial sentence from your page to ensure it appears here. Do you remember how we identified crucial sentences using WWJD (What would JavaScript Do)?
Make sure important elements are accessible to Google.
To illustrate the problem I like to use the Disqus.com case.
Users get a fully-featured website while Google is… getting an empty page. This is something that you will notice by using the URL Inspection tool in Google.
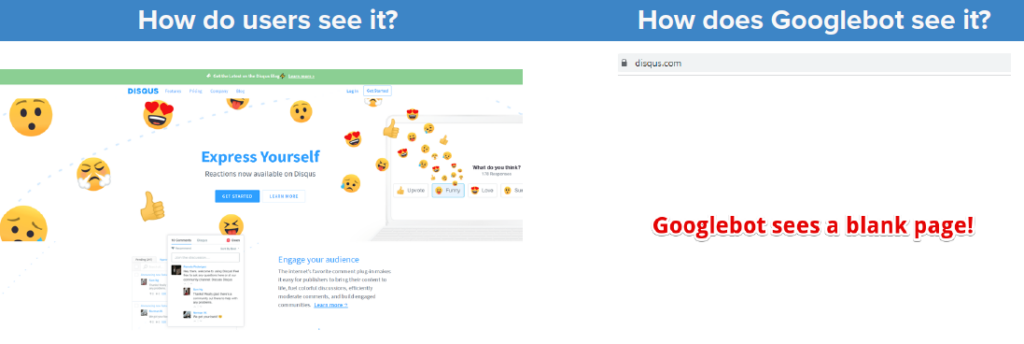
Edit: Disqus.com fixed this issue. However, such an issue was apparent on Disqus.com for over 4 years.
Now I’ve taught you how to check if Google can properly render your website.
But the question is: when should you check it? There are a few common scenarios:
Some of the more advanced people will be thinking about whether they should use Live test or check indexed version.
So I am more of a fan of the indexed version check.
Live check can be helpful if you need a screenshot (such a feature is not available in the indexed version)
Even now, in 2024 it’s very important to check if Google can properly render your content.
This can help you diagnose crawling, ranking and indexing issues.
A few years ago, I noticed a significant change in the SEO visibility of Giphy.com, a widely-used meme website, during one of Google’s core updates. Giphy experienced a drastic 90% drop in SEO visibility, which was a clear indication that drops in traffic during core updates might be closely tied to these updates.
In this article, I’ll share some intriguing cases of traffic loss linked to indexing issues, focusing on the recent October Spam Update.
The first case is particularly noteworthy. During the October Spam Update, Google deindexed 22% of this website’s pages on October 10th, leading to a 60% drop in SEO traffic.
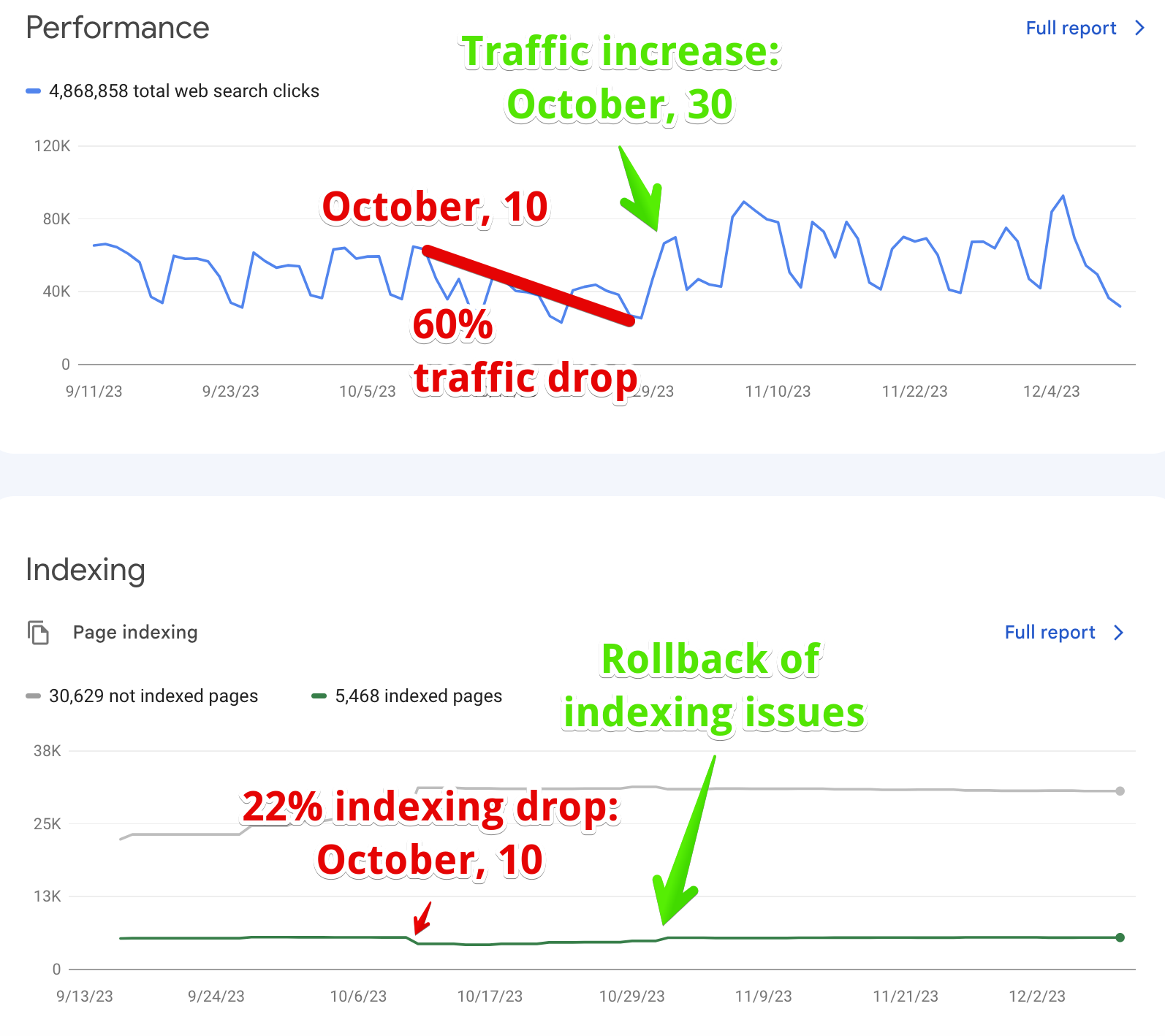
However, as you can see on the chart above, by the end of October, a rollback occurred. The site’s indexed pages and traffic returned to their original levels.
Interestingly, the site then began to receive even more traffic than before. This raises the question: Was the October Spam Update too harsh on this website?
Another website experienced a 35% decline in traffic around the same time in October. Coinciding with this, Google deindexed 50% of its pages on October 14th.
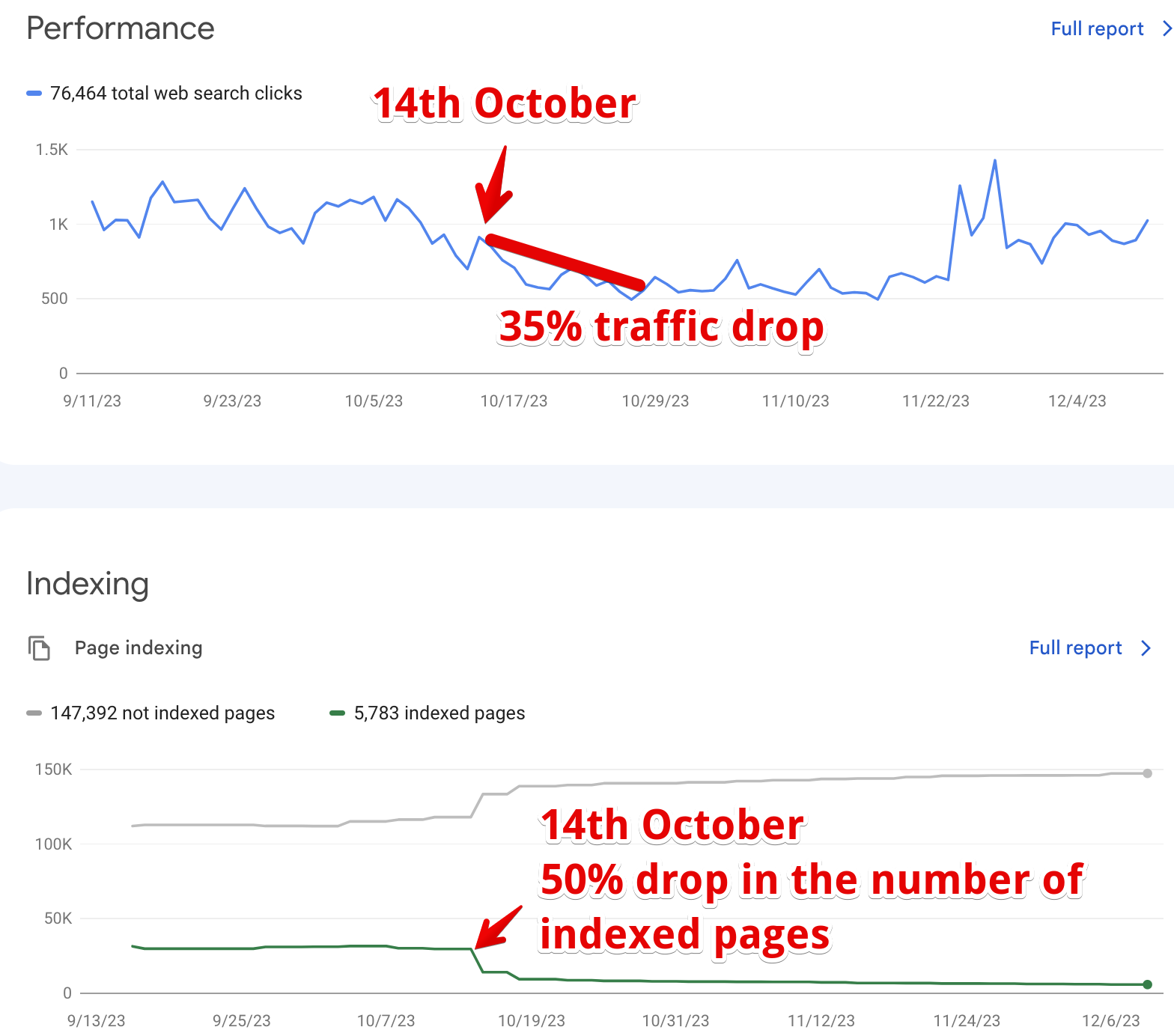
Was this just a coincidence? I don’t think so 😀
The third case is perhaps the most fascinating. On October 7th, we observed a simultaneous drop in both traffic and indexing.
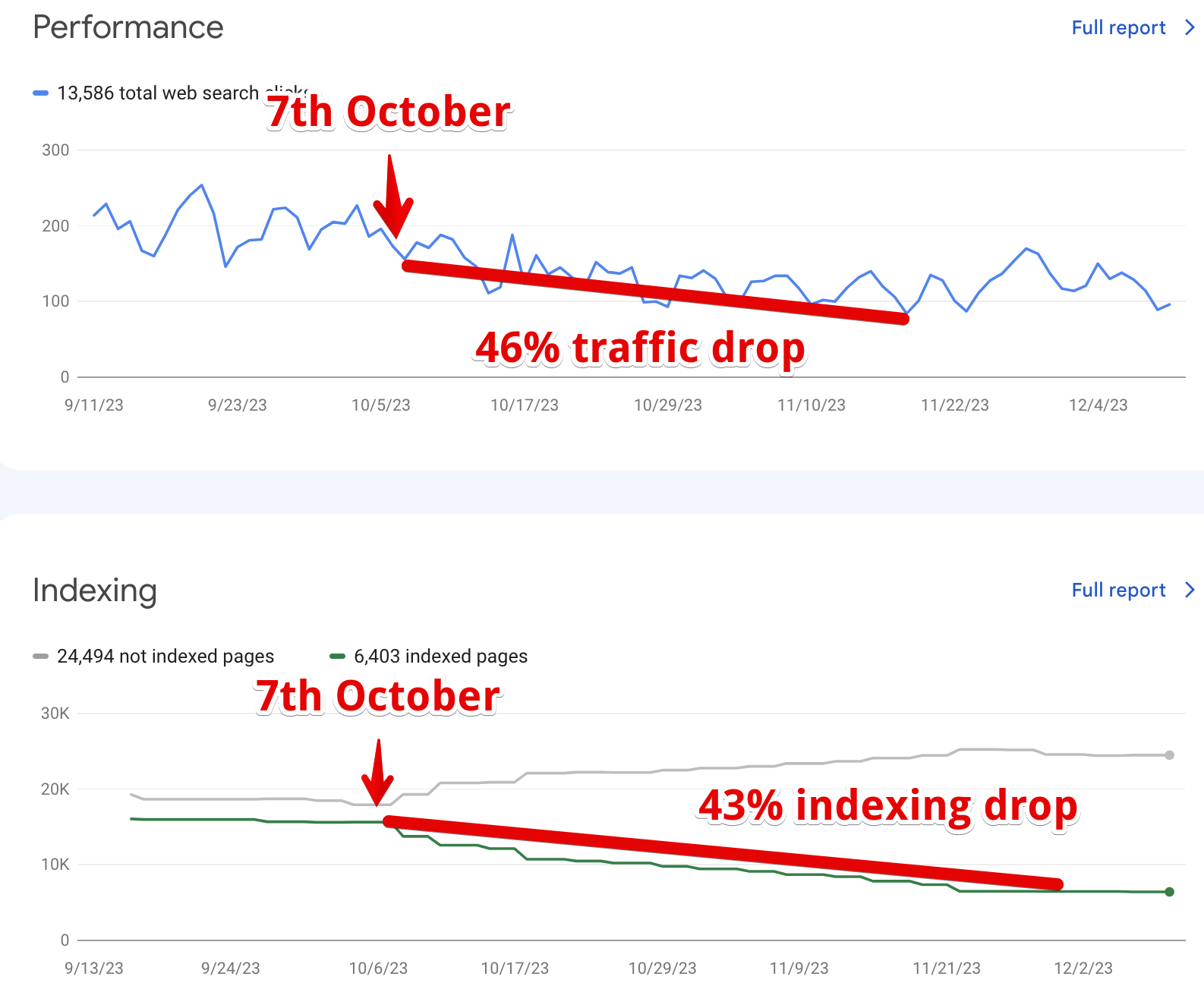
What sets this case apart? Shortly after the main traffic decline, Google deindexed numerous pages due to duplicate content issues.
However, this wasn’t your typical duplicate content problem.
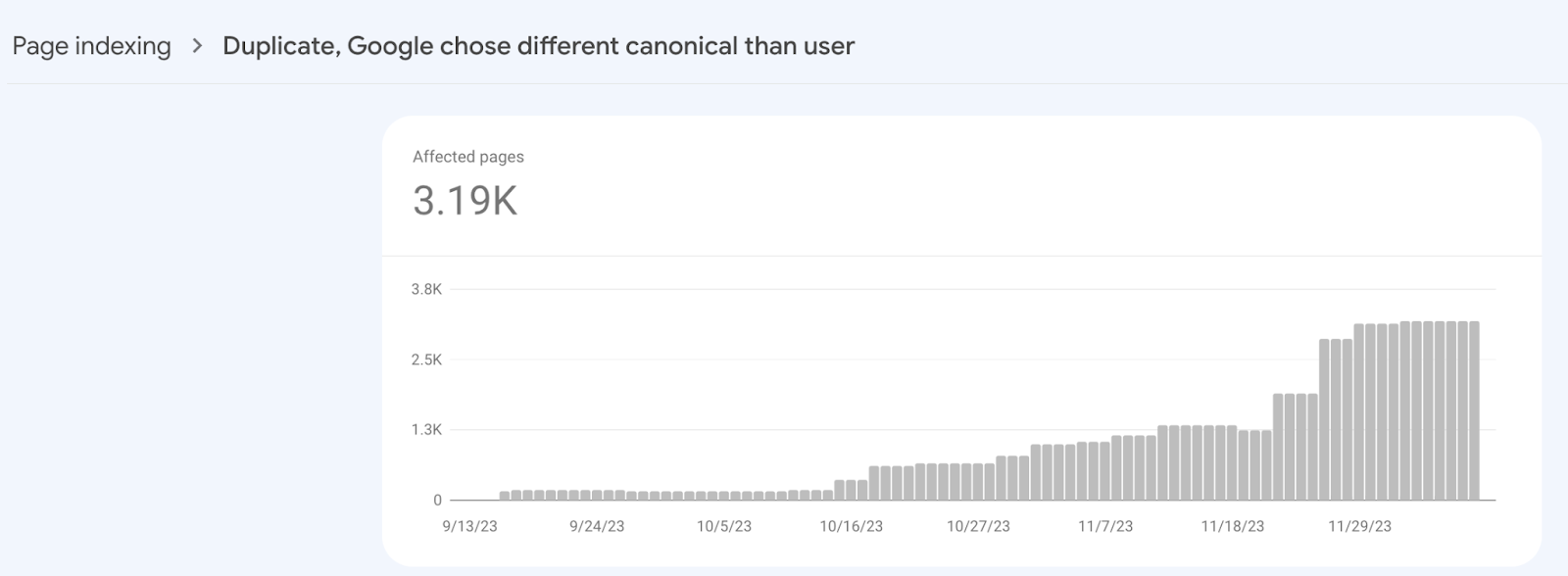
Google mistakenly identified many product and category pages as duplicates of the homepage, which was clearly inaccurate and sonded like a Google bug.

This wasn’t an isolated incident. Last year, I noticed four similar cases and wrote about them in an article Google’s duplicate detection algorithm is broken.
Gary Illyes from Google shortly later suggested on LinkedIn that such duplicate content issues might stem from Google’s challenges in rendering JavaScript content.
Now, a year later, we have gained more insights. In this particular case, the website was JavaScript-driven, leading me to believe that Google’s difficulty in rendering JavaScript is causing the problem. With JavaScript disabled, these pages appeared very similar, which likely triggered the duplicate content flag.
If you’re facing similar issues with duplicate content, I recommend checking a sample of affected pages to see if they are indeed similar. If not, investigate potential JavaScript SEO issues.
In addition to these cases, I’ve found several other instances where Google deindexed numerous pages during recent core updates, resulting in significant traffic drops.
Whenever I notice a drop in traffic, I review every report in the Google Search Console to look for clues about what happened.
I particularly focus on indexing reports to determine if the traffic drop could be related to indexing issues. This includes overall indexing trends and specific issues like ‘Crawled – currently not indexed,’ which might indicate deindexing by Google.
Recently, Twitter.com faced a significant decline of 30% in their SEO traffic, as estimated by Sistrix. Twitter no longer ranks in Google for many prominent keywords, including “Trump”, “Yankees”, or “Jennifer Lopez”.
The potential cause behind this issue is rather straightforward.
Twitter’s CEO, Elon Musk, made an announcement expressing their intention to limit bot activity on the platform.
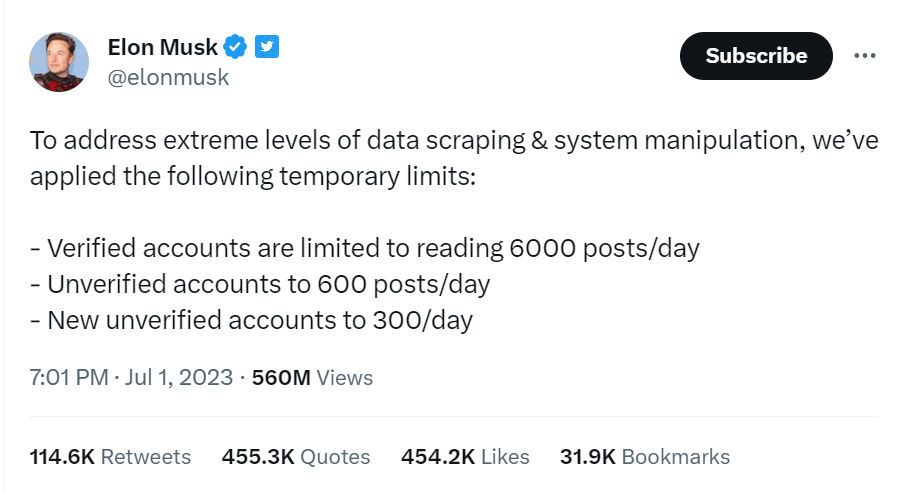
However, it appears that this limitation has unintentionally affected Googlebot as well. Unless Twitter addresses this technical problem, the consequences could persist.
Although we lack complete certainty without access to Twitter’s internal data, several indicators strongly suggest that Twitter is blocking Google and this has had a lot of negative consequences, including traffic decline!
Barry Schwartz observed a substantial reduction in the number of indexed pages associated with Twitter.
| Estimated number of indexed pages BEFORE Twitter policy change | Number of indexed pages AFTER Twitter policy change | Drop |
| 471M | 188M | 62% |
b. Visibility Drop:
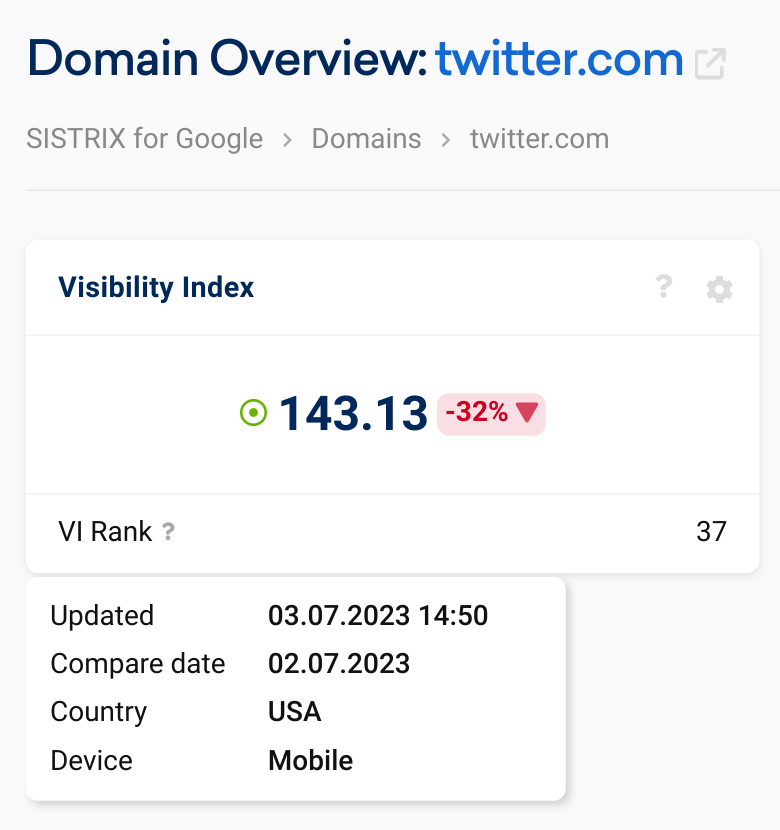
Steve Paine from Sistrix noticed a significant 30% drop in visibility for Twitter.com (in the US market).
c. Personal Investigation:
In my own investigation, I utilized a rendering proxy to assess how Twitter pages are presented to Google. The results indicated that Google’s bots are being blocked.
Findings of my personal investigation:
During my investigation, I made a screenshot of how Google’s URL Inspection tool renders certain Twitter posts.
And it shows Googlebot is blocked.
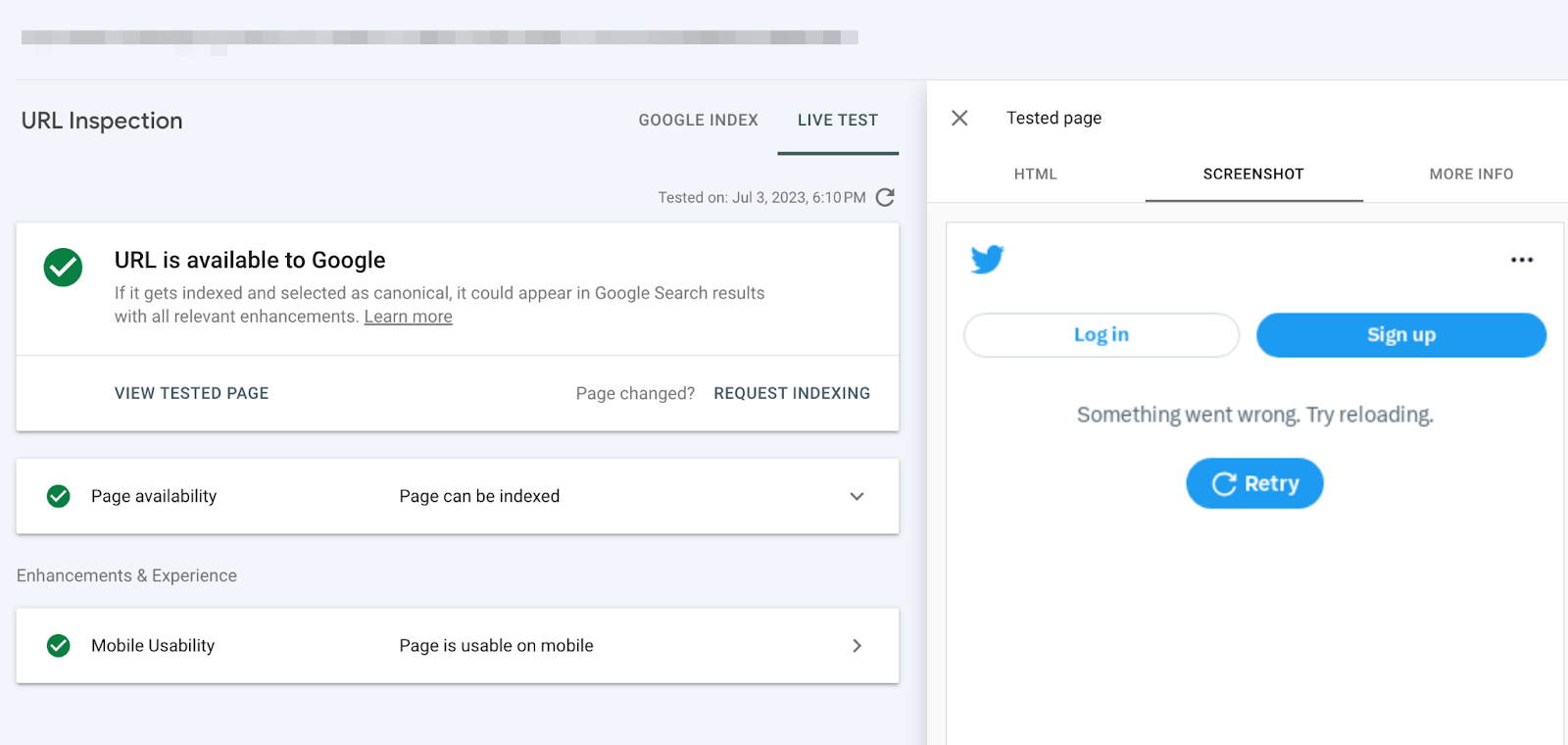
Although this evidence is not entirely conclusive due to recent changes in the user-agent of the URL Inspection tool, it provides valuable insights into the situation.
All this evidence speaks to the fact that Twitter is blocking Googlebot and this is having a negative impact on their SEO traffic.
P.S. blocking Googlebot is not the only SEO problem Twitter has. During my personal investigation I also noticed JavaScript SEO sabotages Twitter’s SEO traffic. I will explain it in one of my upcoming articles, so stay tuned!
Rather than assigning blame to specific individuals, it is important to recognize that decisions within Twitter, including layoffs and major changes are primarily made by the CEO Elon Musk.
Consequently, it is conceivable that this decision was implemented without consulting Twitter’s SEO team.
While it is understandable that Twitter wishes to limit the number of bot-driven interactions, as they consume valuable traffic, disrupt analytics, and scrape content, it is crucial to exempt Googlebot and Bingbot from these restrictions. This can be accomplished through development adjustments.
Twitter’s developers can identify Googlebot either through user-agent or by utilizing a list of IP ranges provided by Google. By whitelisting Googlebot, Twitter can ensure that their pages remain accessible to search engine crawlers without compromising their desired limitations.
However, in some areas this can be considered cloaking; to mitigate risk you can add structured data, as explained below.
More information can be found in the Google’s documentation.
Firstly, by implementing the proposed solutions, Twitter can strike a balance between restricting bot activity and maintaining visibility in search engines. This change should be relatively straightforward to implement and would benefit both Twitter as a company and its users.
Secondly, this is an open message for website owners, CEOs – whenever you implement huge changes like this – restricting robots – always consult the SEO team!
In an article I wrote a while ago, I explored why Giphy.com lost a whopping 90% of its traffic. The diagnosis was clear: Google detected a significant portion of low-quality content on the website. As a result, this section was deindexed, leading to a significant drop in traffic.
Now, let’s delve into how this process works and how to protect your website. We’ll examine how low-quality content can harm:
John Mueller from Google once said, “Usually when I see questions like this where it’s like, we have a bunch of articles and suddenly they’re not being indexed as much as they used to be, it’s generally less of a technical issue, and more of a quality issue.”
He further explained, “It’s more a matter of just our algorithms looking at that part of the website, or the website overall and saying, we don’t know if it actually makes that much sense for us to index so many pages here. Maybe it’s OK if we just index a smaller part of the website instead.“
From John’s statement, it’s clear that low-quality content on some pages can cause significant deindexing problems for an entire website.
How can you determine if you’re affected? Check for the number of pages classified as “Crawled – Currently Not Indexed,”, especially around the date of core updates. If you see a spike in the number of affected pages, it might be due to sitewide quality issues.
For instance, I noticed a few significant drops around the Google Spam Update, when Google was significantly cutting down indexed pages. If you’re curious, read the article that I wrote.
Google has mentioned that low-quality content on some parts of a website can impact the site’s overall rankings:
Think about it like this: If you go to a restaurant and have a meal that you enjoy, you’ll likely return. But if your next few meals there are disappointing, you’ll probably stop recommending that restaurant. It’s the same with Google. Why would Google recommend a website to users if there are many low-quality pages on it?
So, if you see a ranking drop in your Google Search Console or any other ranking monitoring tool, analyze the quality of your website overall. Are there any low-quality content pages indexed in Google?
According to Google’s documentation, if Google spends too much time crawling low-quality URLs, it may decide that it’s not worth the time to examine the rest of your site.
This situation could lead to many pages being classified as “Discovered Currently Not Indexed,” which, according to our statistics, is the second most common indexing problem.
Regular monitoring of your website is crucial to ensure there are no indexed low-quality pages.
How to do this?
For example, you might want to verify that empty search results from your internal search engine aren’t indexed. If your website displays a “0 result found” message, you’ll want to make sure Google hasn’t indexed it.
How do you do this? It’s straightforward. Just type the following into Google’s search bar: “0 results found for” site:example.com.
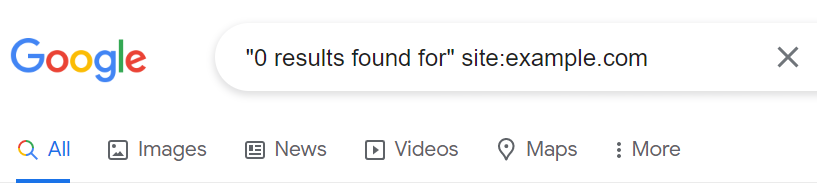
Follow the same procedure with similar patterns of low-quality URLs.
This is the first and most basic step. You can then review both crawl stats in Google Search Console and in the server logs to see if Google is not wasting its crawl budget on low-quality pages.
By staying proactive in monitoring and eliminating low-quality content, you can ensure that your website maintains good standing with Google; this is essential for your site’s visibility and ranking.
In conclusion, maintaining high-quality content is crucial for your website’s health, affecting everything from indexing and rankings to your crawl budget. Keep an eye on your content quality to ensure your site stays in good standing with Google.
Anytime you have a ranking or indexing drop, think if it can be related to low-quality content on some parts of your website.
Google doesn’t index all content on the internet. With limited resources and an ever-growing amount of online content, Googlebot can only crawl and index a small fraction of it.
To quote Google’s blog: “Google has a finite number of resources, so when faced with the nearly-infinite quantity of content that’s available online, Googlebot is only able to find and crawl a percentage of that content. Then, of the content we’ve crawled, we’re only able to index a portion.”

This challenge has grown more significant over time, making indexing even more difficult today, when many businesses generate content using artificial intelligence and Google needs to be more selective about which pages will end up in the Google’s index.
Let’s learn why and how to stay on top of this.
As more website owners use artificial intelligence (AI) to create content, the quality of AI-generated content becomes a concern. Google needs to build more sophisticated algorithms to detect low-quality content, regardless of the source.
The stake is high.
If Google is not successful at filtering low-quality AI-generated content, it will massively reduce the quality of its search results. It’s easy to foresee the implications: Google may lose lots of users, and suffer decreased revenue.
Personally, I expect this to have a massive impact not only on those websites heavily reliant on Artificial Intelligence but all websites with content that could be treated as borderline.
It’s happening now.
Sometimes, a page isn’t indexed not because of its content but due to a sitewide issue. Google might not see the overall website, or even a part of it, as worth indexing. Improving the overall quality of your website can help with indexing.
Here is confirmation from Google’s John Mueller:
“Usually when I see questions like this where it’s like, we have a bunch of articles and suddenly they’re not being indexed as much as they used to be, it’s generally less of a technical issue, and more of a quality issue. (…) It’s more a matter of just our algorithms looking at that part of the website, or the website overall, and saying, we don’t know if it actually makes that much sense for us to index so many pages here. Maybe it’s OK if we just index a smaller part of the website instead.”
But even if your website is of a high quality, it may end up having problems with indexing if servers can’t handle Googlebot’s request.
As pointed out in Google’s Gary Illyes’ article, “Google wants to be a good citizen of the web”. So it doesn’t want to bother your servers too much.
The rule is simple.
The diagram below coming from one of our clients is a perfect illustration of the problem.
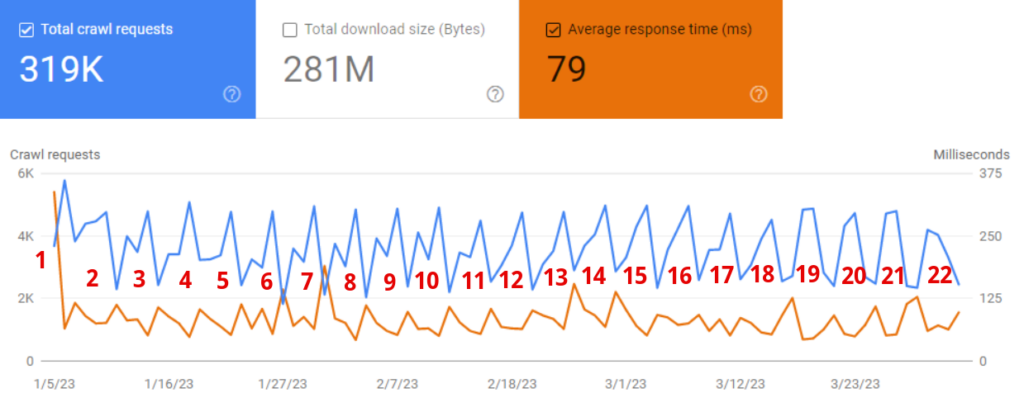
Just look what happens when the average response time goes down (orange line). At the same time, the total number of requests goes up.
Commonly slow servers lead to massive problems with pages classified as “Discovered – currently not indexed”.
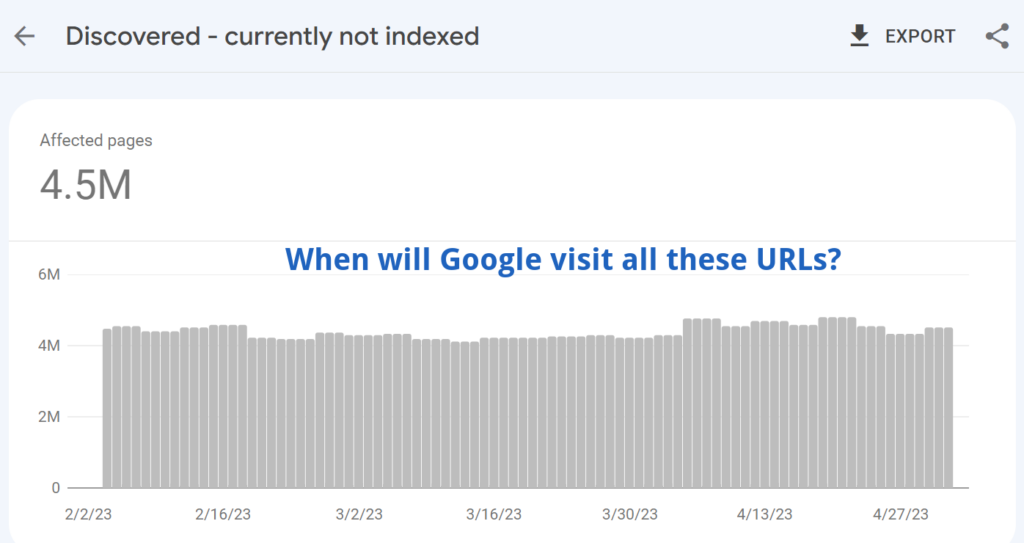
Important note: Speed is not just about server performance but also overall website performance. Here is the proof – slow rendering means slow indexing.
Problems with indexing are not only caused by low-quality content issues.
Let me explain why Google has to keep its index lean.
Indexing is expensive for Google as it requires rendering pages and using complex algorithms like MUM and BERT. As a result, Google is cautious about deciding which URLs to include in its index.
According to Google, rendering alone takes 20x more resources.

With extremely costly algorithms such as MUM or BERT, we cannot estimate the real cost.
It’s worth mentioning what Google once said that “Some of the models we can build with BERT are so complex that they push the limits of what we can do using traditional hardware”. Consider the fact that BERT is used for every user query and MUM is even more costly.
Oversimplified calculation: Google’s indexing cost is now over 40x more than just a few years ago.
This is why Google thinks twice about whether a given URL should be included in Google’s index.
Users want quick search results, so Google must maintain a lean index to avoid longer wait times.
Let’s imagine that the size of Google’s index has doubled. All things being equal, it could take much longer for users to find results.
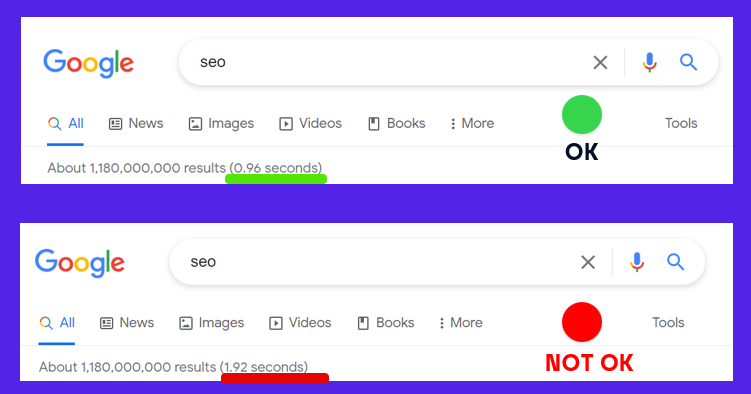
This is why Google needs to keep its index lean and be selective about which pages get indexed.
Even if Google indexes a page, there’s no guarantee it will remain indexed forever. When data centers are too busy, some content may be deindexed.

Here are just two examples of two core updates that occurred in the last few months that had a massive impact on indexing.
I expect that future core updates will cause massive deindexation across various niches, in particular: e-commerce stores, classifieds, and marketplaces. More website owners can expect a rising number of pages classified as:
How do I deal with the problem of Google deindexing your content?
This process is beneficial for two reasons:
To sum up, we can see that Google cannot afford to index all pages.
Google is forced to cut some pages from the index because:
If you suffer from indexing issues, check out ZipTie.dev! We have plenty of tools to handle your indexing issues. Try us out for free with a 14-day trial!
The Index Coverage report in Google Search Console allows you to check the indexing statuses of your pages and shows you any indexing problems Google encountered on your website.
Regular monitoring of these statuses is extremely important. It allows you to quickly spot any issues that can keep your pages away from Google’s index and take action to resolve them.
But to take action, you need to understand what each status means.
The documentation on the Index Coverage report provided by Google is not always clear, and it doesn’t cover common scenarios and all the potential causes of a given status. That’s why I created this article to summarize the Index Coverage report statuses and provide you with information on what each status indicates.
Before I jump into explaining the Index Coverage report statuses, I’d like to take a moment to discuss the names of the statuses.
Different statuses might indicate the same problem, but they differ only in the way Google discovered the URL. More specifically, the word “Submitted” specifies that Google found your page inside your sitemap (a simple text file listing all of the pages you want search engines to index).
For example, both statuses “Blocked by robots.txt” and “Submitted URL blocked by robots.txt” indicate that Google can’t access the page because it’s blocked by robots.txt (I’ll explain this status later). However, you explicitly asked Google to index your page by putting it inside your sitemap in the latter case.
If your page reports a status with the word “Submitted”, you have two options: resolve the issue or remove the URL from your sitemap. Otherwise, you’re asking Google to visit and index a page that is impossible to index. This situation can lead to wasting your crawl budget.
Crawl budget indicates how many pages on your website Google can and wants to crawl. If you own a large website, you need to ensure Google spends your crawl budget on valuable content. By monitoring the statutes containing the word “Submitted”, you can make sure you don’t waste your crawl budget on pages that shouldn’t be indexed.
Now, let’s talk about the Index Coverage report statuses in detail.
In 2021, I researched the most commonly occurring indexing problems. It turned out that these two statuses were particularly common:
Both of the statuses indicate that your page is not indexed. The difference lies in whether Google visited your page already or not. The table below sums up the differences between these statuses:
| Status | Discovered | Visited | Indexed |
| Crawled – currently not indexed | Yes | Yes | No |
| Discovered – currently not indexed | Yes | No | No |
Now, let’s take a closer look at each of these statuses.
The Crawled – currently not indexed status indicates that Google found and crawled your page, but it decided not to index it.
There might be many reasons for this status to appear. For example, it might be just an indexing delay, and Google will index the page soon, but it also might indicate a problem with your page or the whole website.
In my guide, How to Fix Crawled – Currently Not Indexed, I listed potential causes of this status and ways of fixing them. In short, the primary reasons for the Crawled – currently not indexed status include:
The Discovered – currently not indexed status means that Google found your page, but it hasn’t crawled or indexed it.
There are a lot of reasons that can cause this status. Gosia Poddębniak explained all of them in her article How To Fix “Discovered – Currently Not Indexed” in Google Search Console, along with the solutions to each problem. The primary factors causing the status include:
Google wants to index pages with distinct information to provide its users with the best possible results and not waste its resources on duplicate content. That’s why when it detects that two pages are identical, it chooses only one of them to index.
In the Index Coverage report, there are two main statuses related to duplicate content:
The above statuses indicate that a page is not indexed because Google chose a different version to index. The only difference is whether you tried to tell Google which is your preferred version using a canonical tag (an HTML tag indicating which is your preferred version if more than one exists), or you left no hints, and Google detected duplicate content and chose the canonical version on its own.
| Inspected page | Indexed page | Did you declare a canonical tag? | Why isn’t the inspected page indexed? | |
| Duplicate without user-selected canonical | Page A | Page B | No | Google decided on its own that Page A and B are duplicated and chose Page B as the canonical one. |
| Duplicate, Google chose different canonical than user | Page A | Page B | Yes – Page B has a canonical tag pointing to Page A. | Your canonical tag wasn’t obeyed. Google decided that Page B is the canonical one. |
A canonical tag is only a hint, and Google is not obligated to respect it.
The Duplicate, Google chose different canonical than users status indicates that Google disagreed with your canonical tag, and chose a different version of the page to index instead.
If the page’s versions are identical, Google choosing a different version than you might not bring any consequences to your business. However, if there was a meaningful difference between the versions and Google picked the wrong one, it might decrease your organic traffic by displaying the wrong version to the users.
One of the main reasons for the status is inconsistent signaling, e.g., you added the canonical tag to one version of a page, but internal links and sitemap indicate that a different version is the canonical one. In that case, Google needs to guess which is the real canonical page and might ignore your canonical tag. That’s why it’s crucial to ensure you are consistent and all of the signals point to one version.
You can find more possible causes and solutions for Duplicate, Google chose different canonical than user in my colleague’s article How To Fix “Duplicate, Google chose different canonical than user” in Google Search Console.
Duplicate without user-selected canonical indicates that your page is not indexed because Google thinks it’s duplicate content, and you didn’t include a canonical tag.
I treat this report as an opportunity to see what type of pages Google detects as duplicate content. It allows you to take action and consolidate the content by, e.g., redirecting all versions to one page or using a canonical tag.
In the Index Coverage report, there’s also a status called Duplicate, submitted URL not selected as canonical. It indicates the same issue as Duplicate without user-selected canonical, but as I mentioned at the beginning, the page reporting Duplicate, submitted URL not selected as canonical, was found inside a sitemap.
The statuses in this chapter indicate that a page is not indexed because you explicitly told Google not to index them, and the search engine respected your wish.
The noindex tag is a very powerful tool in the hands of a website owner. It’s an HTML snippet used to tell search engines that the URL shouldn’t be indexed.
Noindex is a directive, so Google has to obey it. If Google discovers the tag, it won’t index the page, and it will mark it as Excluded by ‘noindex’ tag (or Submitted URL marked ‘noindex’ if you included this page in your sitemap).
In a situation when the page reporting Excluded by ‘noindex’ tag really shouldn’t be indexed, you don’t need to take any action. However, sometimes a developer or an SEO wrongly adds the noindex tag to important URLs, resulting in those pages dropping out from Google’s index. I recommend you carefully review a list of all the pages reporting Excluded by ‘noindex’ tag to ensure no valuable page was mistakenly marked as noindex.
The Alternate page with proper canonical tag status indicates that Google didn’t index this page because it respected your canonical tag.
What does this mean for you?
In most cases, you don’t need to take any action. It’s mostly information that everything works correctly regarding this URL. However, there are two cases when you shouldn’t skip this report:
Before Google can index your page, it needs to be allowed to crawl it to see its content.
Crawling can be blocked for many reasons. You might do it on purpose to keep search engines away from specific content and save your crawl budget, but it also might be an effect of a mistake or malfunction.

In the table below, you can find the Index Coverage report statuses indicating an issue that results in crawling being blocked.

Google wants to ensure that the pages it shows for Google users are of high quality. To fulfill this mission, it uses advanced algorithms such as a soft 404 detector.
Google marks pages as soft 404s when it detects the page doesn’t exist, even if the HTTP status code doesn’t indicate it.
If a page is detected as soft 404, it won’t get into Google’s index. In such cases, Google will mark it either as:
However, like every mechanism, a soft 404 detector is prone to false positives, meaning your pages may be wrongly classified as soft 404 and eventually deindexed. Common reasons for this situation include:
If you’re interested in learning more about soft 404s, I recommend you check out Karolina Broniszewska’s article on soft 404s in SEO, where she covered the topic in detail.
Understanding the Index Coverage report is essential to give your pages the best chances of being indexed.
Unfortunately, Google’s documentation doesn’t provide you with all of the pieces of information necessary to diagnose and resolve problems on your website. It’s not always clear whether a status requires your immediate attention or is just information that everything is going well.
I hope my article helped you understand how to look at the Index Coverage report and made analyzing the statuses a little easier. Remember that regular monitoring of the report is the key to spotting technical SEO issues quickly and preventing your business from losing organic traffic.
As announced on October 18th, 2021, Bing and Yandex are adopting IndexNow – a shared protocol that will allow website owners to notify these search engines whenever their website content is created, updated, or deleted.
In my opinion, it might be the most significant piece of news in the technical SEO world since Googlebot started using evergreen Chromium to render content, although it doesn’t change much for now.
It’s a giant step towards limiting crawling activity in favor of indexing APIs. Whether or not Google follows suit, IndexNow is a sign of things to come and a clear signal that existing indexing pipelines are subject to change.

IndexNow is a protocol that allows site owners to notify multiple search engines of new or modified content on their websites.
While we still don’t have all the details, it’s likely that Bing decided to build on its Content Submission API, released in September 2021, and create an open indexing protocol shared with other search engines that might want to participate.
The official website states the following about the possibility of participation: “Search Engines adopting the IndexNow protocol agree that submitted URLs will be automatically shared with all other participating Search Engines. To participate, search engines must have a noticeable presence in at least one market.”
To ping the participating search engines (at the moment, these include Bing and Yandex), you first need to verify the ownership of your domain.
There are two options to do so:
Then, you can submit either a single URL or a batch of up to 10000 URLs using the following methods:
For now, Google doesn’t support IndexNow, so using https://www.google.com/indexnow?url=url-changed&key=your-key will have the same effect as using https://www.google.com/HeyGooglePleaseIndexMyContent.html, meaning – no effect at all.
That being said, sending a request to either Bing or Yandex will result in both search engines being informed:
“Starting November 2021, IndexNow-enabled search engines will share immediately all URLs submitted to all other IndexNow-enabled search engines, so when you notify one, you will notify all search engines.”
Although the protocol has just been introduced, its creators must have been working with various software providers behind the curtains, because companies like:
already declared that they will support automatically sending rediscovery requests to IndexNow for their clients.
Moreover, popular websites like GitHub, eBay, or LinkedIn, previously adopted Bing’s URL Submission API and are very likely to move towards IndexNow as well.
Even WordPress has its work cut out for it, as Bing provided the open-source code to support IndexNow to help WordPress quickly adopt the shared protocol.
If you aren’t currently using any of these services, don’t worry! We’ve built a tool that you can use to easily submit a list of URLs or your sitemap to IndexNow.

According to the official announcement:
“Without IndexNow, it can take days to weeks for search engines to discover that the content has changed, as search engines don’t crawl every URL often. With IndexNow, search engines know immediately the URLs that have changed, helping them prioritize crawl for these URLs and thereby limiting organic crawling to discover new content.”
Both Bing and Yandex currently have mechanisms in place that you can use to ask for a recrawl of your content, and it’s the same with Google (although Google doesn’t allow submitting multiple URLs at a time).
None of these mechanisms guarantee that your fresh content gets picked up immediately, but they do improve the chances that search engines will pick it up faster than they normally would.
Currently, the main benefit of using IndexNow is that by notifying one search engine, you simultaneously notify others, too. Plus, you can submit URLs in bulks of up to 10000, which is essential for large sites.
This can become even more appealing if more search engines support this shared protocol in the future. If Google joined Bing and Yandex, it would be a game-changer.
You can use IndexNow (and all the other URL submission mechanisms) to help new content get indexed faster, but there are multiple other use cases:
Still, most importantly, “Search engines will generally prioritize crawling URLs submitted via IndexNow versus other URLs they know.” Using IndexNow won’t make Bing or Yandex crawl more of your site, but it can help you influence what gets crawled with a priority.
As it stands right now, IndexNow is not a major revolution in search, although it’s great to see search engines work together to build something that may improve the web for everyone.
But I think this initiative points to a fact of utmost importance: the existing content discovery process that major search engines share is, at least to an extent, subject to change.
The current process is as follows: search engines look for new URLs to visit on websites they already know, following on-page links and sitemaps. Then they make a list of URLs that’s prioritized based on various factors – they’re mostly confidential but a good rule of thumb is that consistent, great quality, and popularity of your domain will keep the search engines coming back.
What this process entails is the constant crawl activity, which search engines need to expand as the web grows exponentially. They have little choice – there’s great, relevant content popping up everywhere and that’s on top of existing popular websites which need regular recrawling to keep the search index as fresh as possible.
What if some of the process of discovering new content could be replaced by a mechanism that would allow site owners to proactively inform search engines when they make changes to their websites?
If this process turned out to be a good alternative, search engines could potentially save resources spent on crawling.
But crawling itself isn’t the main problem with maintaining a large search index of fresh content.
Crawling billions upon billions of pages is definitely a challenge, but it’s rendering them to fully see their contents that’s absurdly resource-consuming.
Google is definitely ahead of the competition when it comes to its ability to render and analyze web content on a scale. While others are catching up, smaller search engines may never be able to spend enough resources on rendering to truly compete with Google when it comes to the quality of their search results.
IndexNow could truly make a difference, particularly for smaller search engines, if it allowed multiple companies to join forces and use a single database of rendered pages to build their search indices.
If you ever suffered from indexing issues with your website, you should follow the discussion around IndexNow very closely.
Time will tell if this initiative will encourage Google to either use IndexNow data to supplement its own search index or come up with its own URL submission solution that’s more scalable than what we currently have in Google Search Console.
Either way, IndexNow an innovative attempt at solving one of the greatest challenges search engines currently face: the abundance of content that needs to be crawled and rendered while an average website gets heavier every year.
I applaud everyone involved in developing this protocol and I’m looking forward to seeing how it affects the web in the future.